
The optimal value is 12.37578346960808
A solution x is
w = [2.35589697 2.25825204]
beta = [-6.84717488]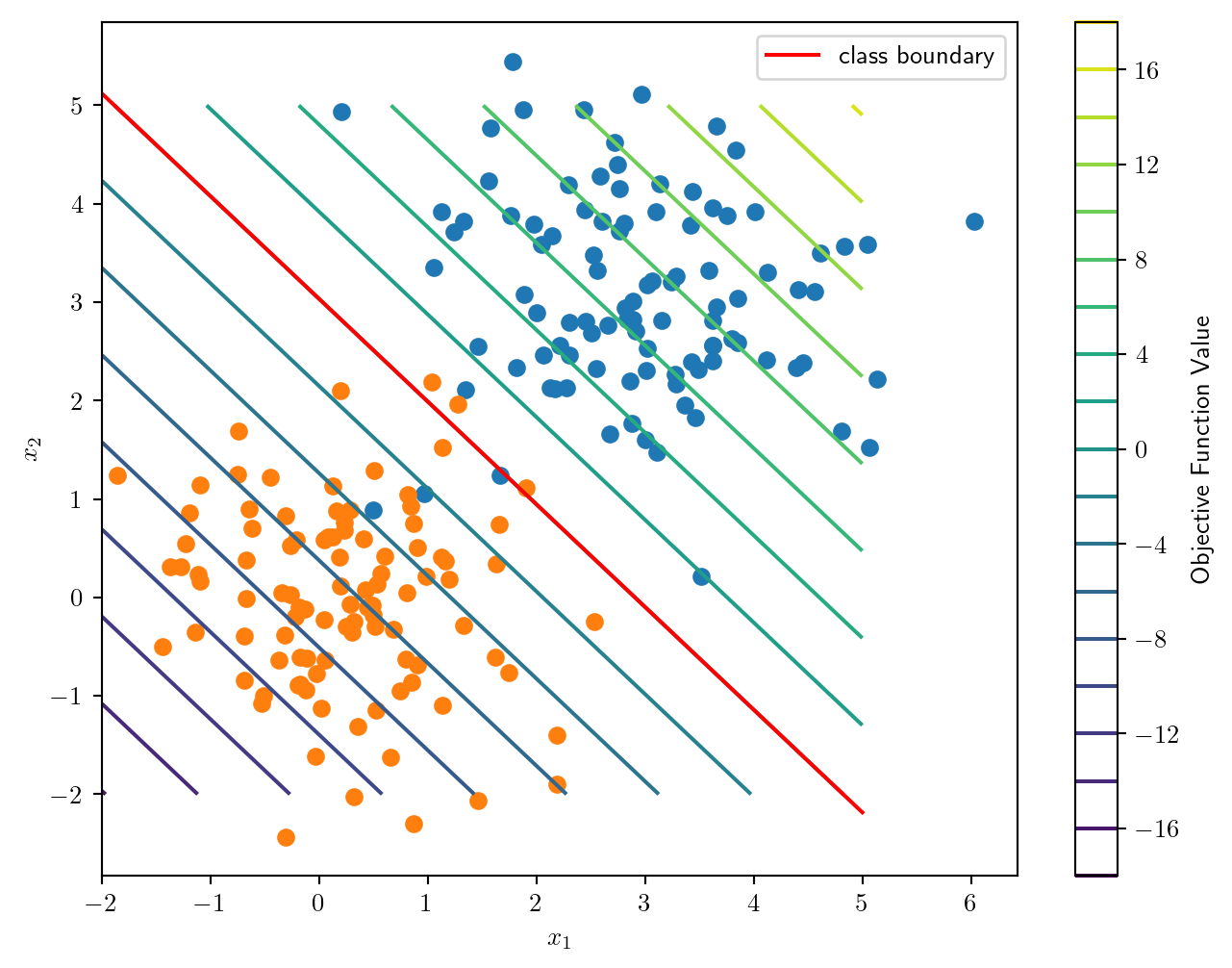
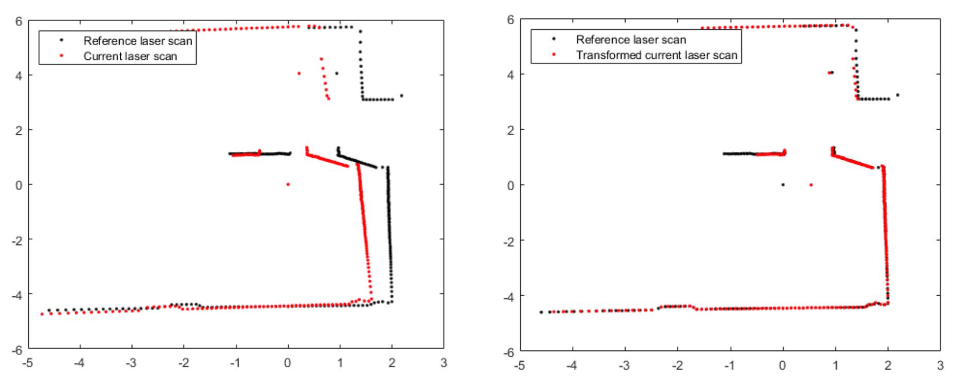
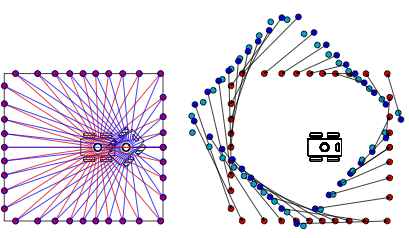
Laser scan taken at two different positions can be aligned to estimate robot motion
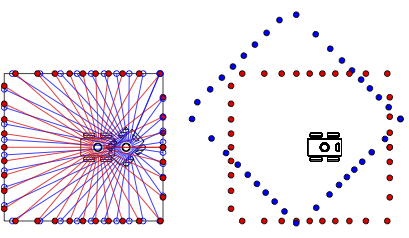
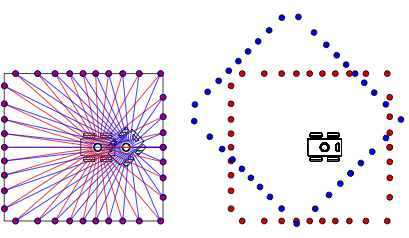
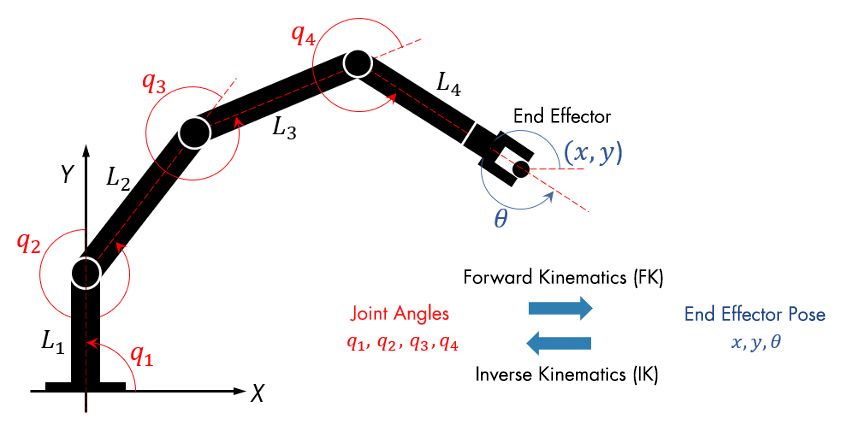
Given joint angles we can predict the end effector pose
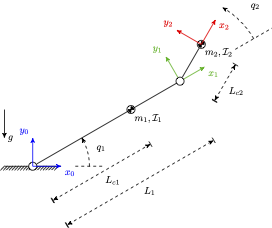
Frame has pose given by
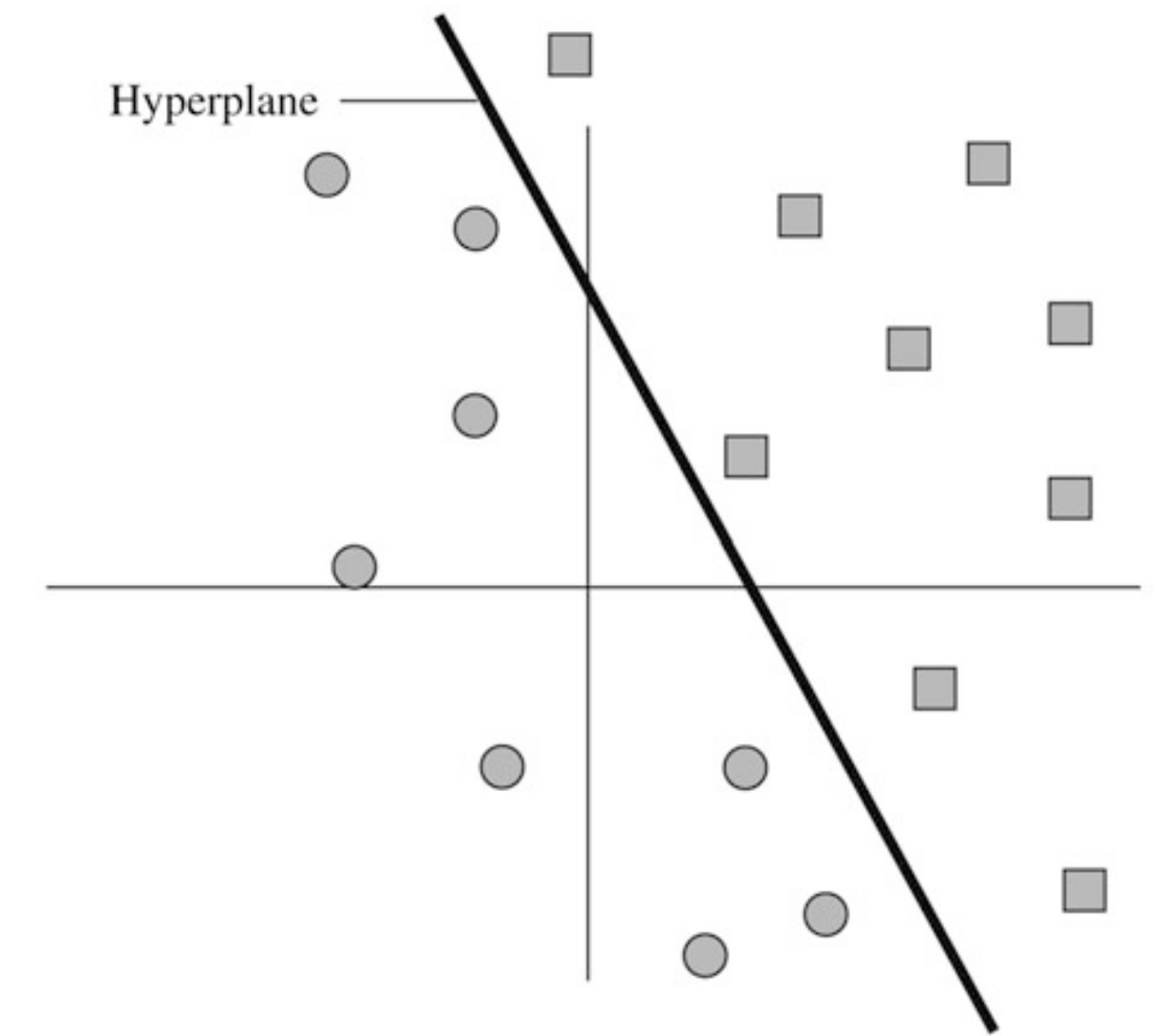
Two clusters of points (red) and (green) in (d=2)
The optimal value is 12.37578346960808
A solution x is
w = [2.35589697 2.25825204]
beta = [-6.84717488]
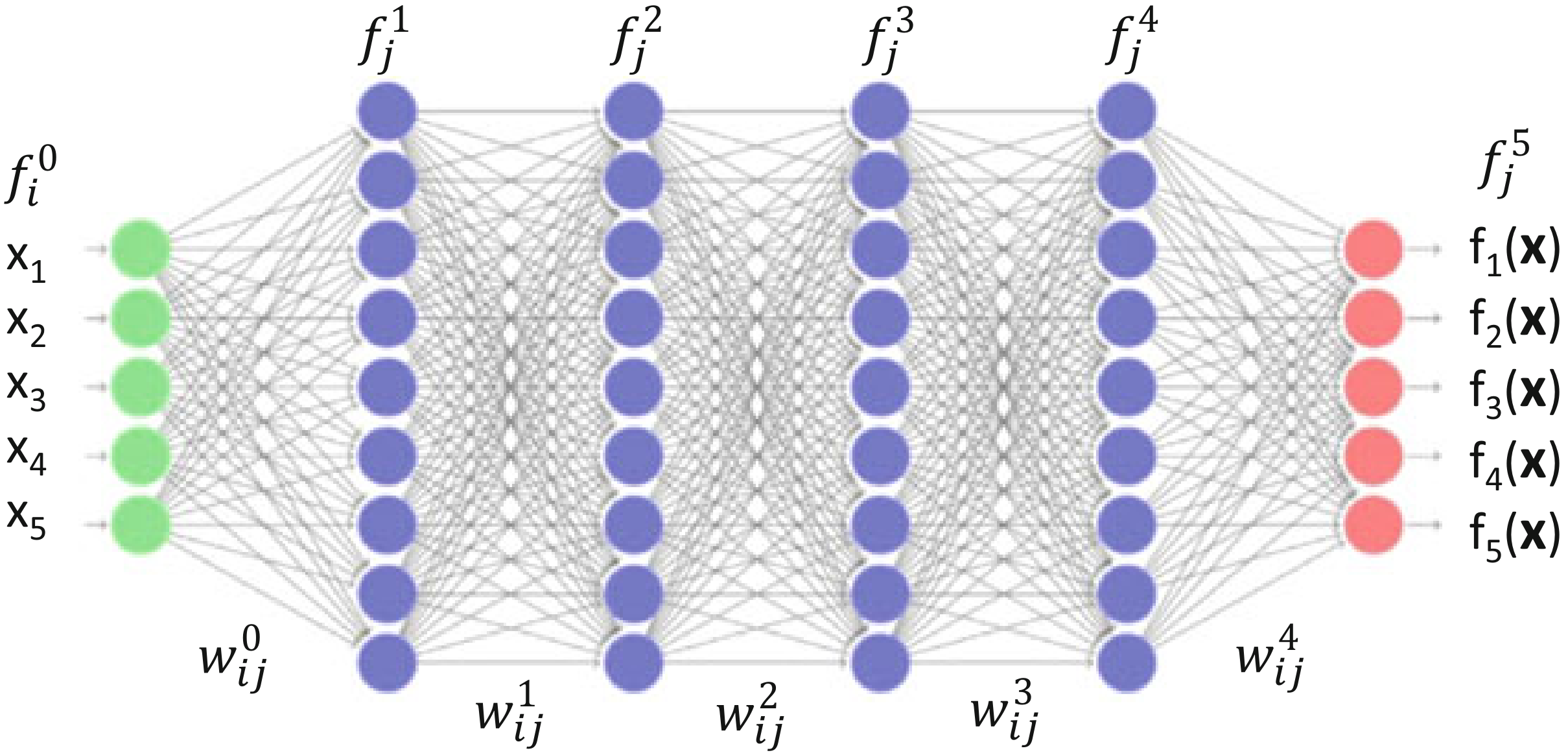
A chain is suspended from two thin hooks that are ft. apart on a horizontal line. Each link is one foot in length (measured inside). We wish to formulate the problem to determine the equilibrium shape of the chain.
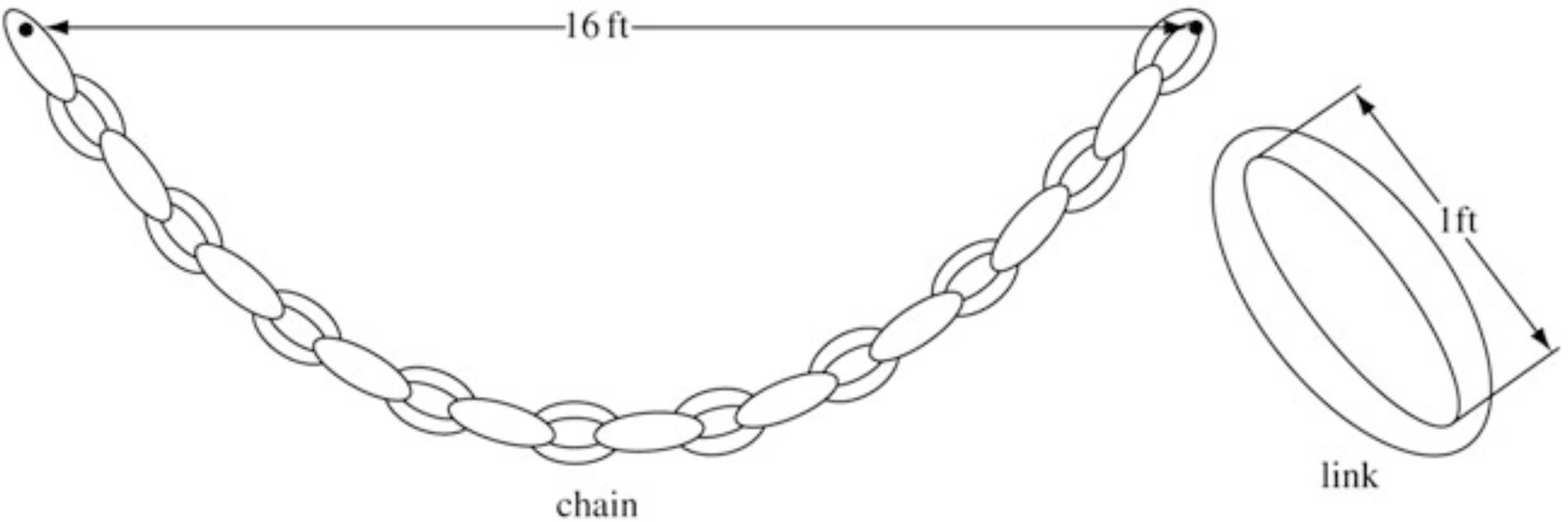
The solution can be found by minimizing the potential energy of the chain.
where for those no-arc pairs .

where is the desired hyperplane.