
Optimization Theory and Practice
Unconstrained Optimization
Instructor: Hasan A. Poonawala
Mechanical and Aerospace Engineering
University of Kentucky, Lexington, KY, USA
Topics:
Solutions
Necessary and Sufficient Conditions
Overview of Algorithms
Example: Curve Fitting
Suppose we have data in the form of pairs
We believe that the model is of the form
A standard approach is to find the values of , by solving where
This is a nonlinear least-square problem.
Solutions
Global minimizer
A point is a global minimizer if for all .
Local minimizer
A point is a local minimizer if there is a neighborhood of where for all , where a neighborhood of is an open set containing .
Strict local minimizer
A point is a strict local minimizer if there is a neighborhood of where for all with .
Taylor’s theorem
Taylor’s Theorem
Suppose that is continuously differentiable and that . Then we have that for some . Moreover, if is twice continuously differentiable, we have that and that for some .
First-order Necessary Condition
FONC
If is a local minimizer and is continuously differentiable in an open neighborhood of , then .
Notice that this is not the same as is a local minimizer
Stationary point
A point is a stationary point if it satisfies
Second-order Necessary Condition
SONC
If is a local minimizer of and exists and is continuous in an open neighborhood of , then and is positive semidefinite.
Positive semidefinite matrix
A matrix is positive semidefinite, denoted1 , if
If for some real matrix , then is positive semidefinite.
Second-order Sufficient Condition
SOSC
Suppose that is continuous in a neighborhood of and that and is positive definite. Then is a strict local minimizer of .
Positive definite matrix
A matrix is positive definite, denoted1 , if
First-order Sufficient Condition
There is no first-order sufficient condition for when it is only differentiable
However, when is also convex, there is.
Convex functions
A function is convex if is a convex set and f for all and .
FOSC for convex
When is convex, any local minimizer is a global minimizer of . If in addition is differentiable, then any stationary point is a global minimizer of .
Summary
| Condition | What we know | What it tells us | Notes |
|---|---|---|---|
| 1st Ord Necessary | is LM1, differentiable | Proof justifies steepest descent | |
| 2nd Ord Necessary | is LM, and exist, are continuous on | and is PSD | |
| 2nd Ord Sufficient | and is PD | is strict LM | Leads to algorithms for finding LMs |
| 1st Ord Sufficient | is convex, is LM | is GM2 | |
| 1st Ord Sufficient | is convex, differentiable, | is GM | Leads to effective algorithms for finding global minima |
Overview of Algorithms
- Recall that the algorithms are iterative
- We need a starting point
- … and a method to produce iterates , ,
- Generally two methods:
- Line Search
- Trust Region
Note
The words method and algorithm are used interchangeably
Line Search Methods
- The algorithm chooses a direction
- Then, minimize on the line defined by . That is, solve
- In practice choose an that makes , not solve Equation 1.
- Practical method uses back-tracking line search to pick given
Line Search Methods
- Two common choices for directions.
- Negative gradient (steepest descent)
- Newton direction:
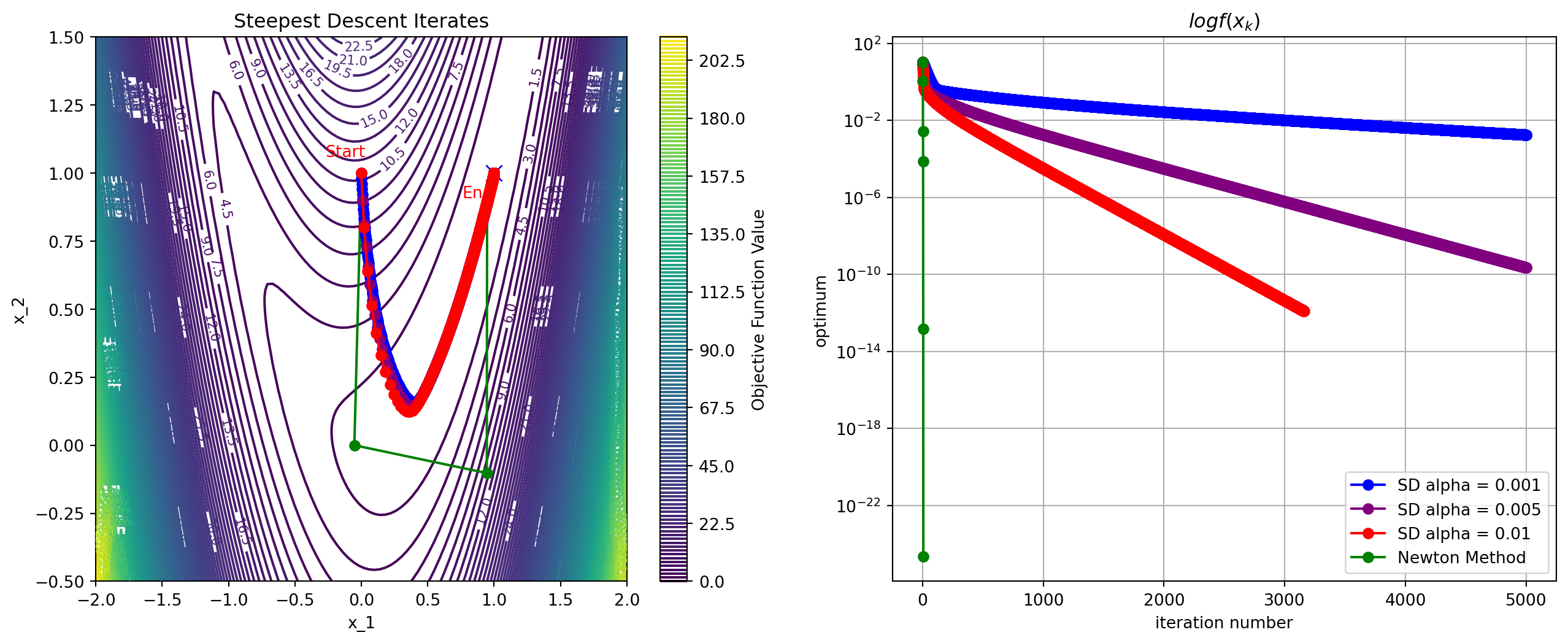
Example: Line Search Algorithms
Important
Newton’s method is not always better
Plotting Code
import numpy as np
import matplotlib.pyplot as plt
# Define the objective function and its gradient and Hessian
def f(x, y):
return #<answer>
def grad_f(x, y):
"""Gradient of f"""
return np.array()
def hess_f(x, y):
"""Hessian of f"""
return np.array()
# Steepest Descent
def steepest_descent(start, alpha=0.1,tol=1e-6, max_iter=50):
# your code
return x, iterates
# Plotting
x = np.linspace(-1, 4, 100)
y = np.linspace(-1, 5, 100)
X, Y = np.meshgrid(x, y)
Z = f(X, Y)
plt.figure(figsize=(8, 6))
# Contour plot of the objective function
contour = plt.contour(X, Y, Z, levels=30, cmap="viridis")
plt.clabel(contour, inline=True, fontsize=8)
plt.colorbar(contour, label="Objective Function Value")
plt.plot(4, 3, 'x', color="blue", markersize=10, label="True Optimum (4, 3)")
# Run Steepest Descent
start_point = [-1.0, 1.0]
optimum, iterates = steepest_descent(start_point)
# Extract iterate points for plotting
iterates = np.array(iterates)
x_iterates, y_iterates = iterates[:, 0], iterates[:, 1]
plt.plot(x_iterates, y_iterates, 'o-', color="blue", label="SD Iterates alpha=0.1")
# Annotate start and end points
plt.annotate("Start", (x_iterates[0], y_iterates[0]), textcoords="offset points", xytext=(-10, 10), ha="center", color="red")
plt.annotate("End", (x_iterates[-1], y_iterates[-1]), textcoords="offset points", xytext=(-10, -15), ha="center", color="red")
# Labels and legend
plt.xlabel("x_1")
plt.ylabel("x_2")
plt.title("Steepest Descent vs Newton's Method for Optimization")
plt.legend()
plt.grid(True)
plt.show()Trust Region Methods
- Approximate near using a model function
- Minimize near by solving
- Common choice: local quadratic Taylor series, with a spherical trust region
(trust-region Newton’s method)
Line Search and Trust Region Methods
In some cases, the two methods overlap 1 yields
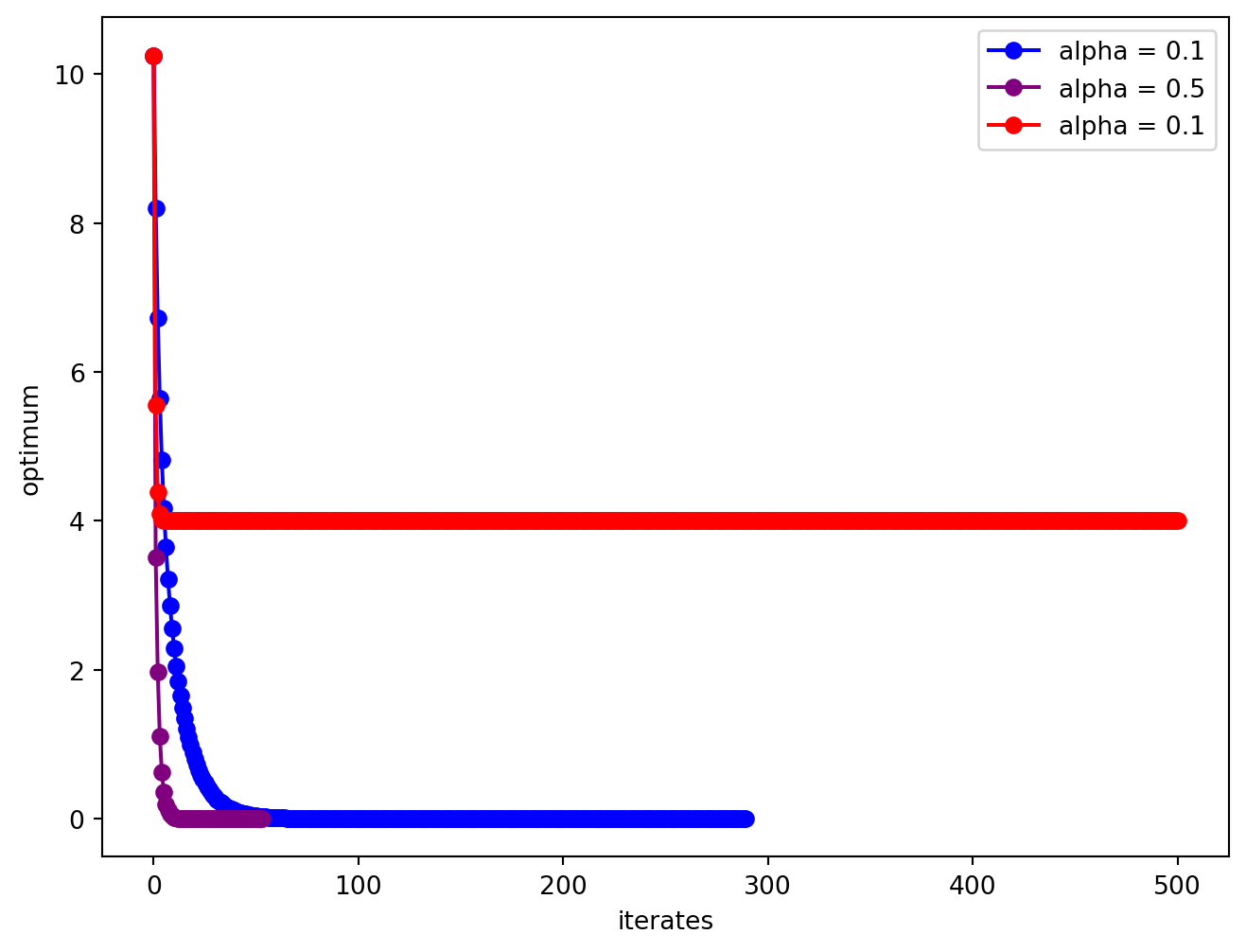
Exercise: Steepest Descent
The optimum is at . Test the behavior of steepest descent algorithms with various constant values of , starting from .
Solution
Systems Optimization I • ME 647 Home