Iterative LQR (iLQR)
Line Search, Forward Pass, and Full Algorithm
Instructor: Hasan A. Poonawala
Mechanical and Aerospace Engineering
University of Kentucky, Lexington, KY, USA
Topics:
Why scales only
Nonlinear forward pass
Backtracking line search
Full algorithm
Recap
The Setup
Nominal trajectory satisfies the true nonlinear dynamics.
Define deviations: , .
Linearized error dynamics around the nominal:
Quadratic cost (second-order Taylor expansion of around nominal):
Unlike LQR, the linear terms and are generally nonzero — the nominal is not yet optimal.
Backward Pass: Q-function
The Q-function for the deviation problem:
Backward recursion (initialize , ):
Backward Pass: Optimal Gains
Minimize over (holding fixed):
| Gain | Expression | Role |
|---|---|---|
| Feedforward — optimization step | ||
| Feedback — state-dependent correction |
Value function updated as: ,
At the optimum , so — identical to LQR.
Forward Pass
The Forward Pass Update
Starting from 1, for :
Discussion: multiplies but not . Shouldn’t we scale the entire update ?
Line Search
Backtracking Line Search
Goal: find such that the updated trajectory strictly reduces cost.
Algorithm:
- Set
- Run nonlinear forward pass with current ; evaluate
- If : accept, update ,
- Else: , repeat from step 2
- After 50 halvings: if , declare convergence
Predicted Cost Improvement
The backward pass implicitly computes the predicted improvement:
This motivates a stronger Armijo condition:
Actual decrease must be at least a fraction of the quadratic model’s prediction.
At convergence: (because ), so and is accepted immediately on the first try — the line search costs nothing.
iLQR: Complete Algorithm
iLQR
Input: initial controls , dynamics , costs ,
1. Rollout: simulate to obtain the nominal trajectory.
2. Repeat until convergence:
2a. Backward pass — init , ; for :
- Compute Jacobians and cost derivatives at
- Compute via the recursion
- Gains: ,
- Update: ,
2b. Forward pass — from , simulate with
2c. Line search — if : accept; else , repeat 2b
2d. Update — ,
iLQR vs. LQR
| Quantity | LQR | iLQR (per iteration) |
|---|---|---|
| Dynamics | ||
| Cost | Quadratic in | Quadratic in ; linear terms nonzero |
| Optimal control | ||
| Feedforward | None ( at optimum) | (drives improvement) |
| Hessian recursion | Discrete Riccati equation | Same Schur complement form |
The backward pass is structurally identical to LQR applied to the deviation problem. The only additions: (1) feedforward gains from nonzero cost gradients; (2) re-linearize each iteration.
Demo: Iterates
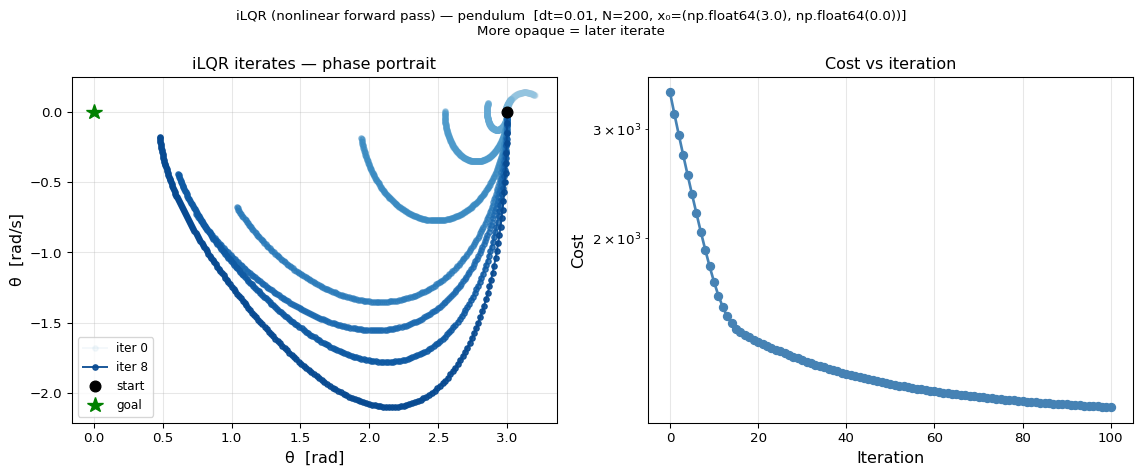
Pendulum swing-up from rad, steps. Snapshots at iterations 0, 1, 2, 4, 8, 15, 25, 50, 100 (darker = later).
Extensions
Beyond iLQR
Differential Dynamic Programming (DDP):
iLQR uses only first-order Jacobians of . DDP adds second-order terms:
- Terms scale as — vanish near the optimum where
- Better convergence rate far from the optimum; expensive and rarely used in practice
- iLQR is sometimes called Gauss-Newton DDP
Beyond iLQR
Natural extensions:
| Extension | Idea |
|---|---|
| Constrained iLQR | Handle via augmented Lagrangian (AL-iLQR) |
| MPC | Re-solve at each timestep with a receding horizon |
| Warm-starting | Initialize next solve from the shifted previous solution |
Summary
Forward pass update:
- scales only — the Newton search direction in
- corrects for nonlinear drift
- Using nonlinear dynamics keeps the trajectory feasible at every iteration
Line search: halve until decreases; signals convergence
Convergence ↔︎ optimality: is the discrete-time PMP stationarity condition
DDP vs. iLQR: dynamics Hessian terms improve convergence rate but are rarely worth the cost
Optimal Control • ME 676 Home