Optimization Theory and Practice
Nonlinear Least Squares
Instructor: Hasan A. Poonawala
Mechanical and Aerospace Engineering
University of Kentucky, Lexington, KY, USA
Topics:
Nonlinear Least Squares
Necessary and Sufficient Conditions
Overview of Algorithms
Forward Problems
We are often trying to work with a model that turns input into output :
where are the parameters of the model .
Example: Given joint angles , where is the robot arm’s ‘hand’? (Forward Kinematics)
Inverse Problems
The inverse problem is to find given and parameters
where are the parameters of the model .
Example: Given where we want the robot’s arm to be, what values should we set the joint angles to? (Inverse Kinematics)
Nonlinear Least Squares
Residual (or error): Loss: Squared Error:
Where is the Jacobian
is the Hessian
Nonlinear Least Squares
Residual (or error): Loss: Squared Error:
Choosing produces some . What values should we want for these?
Nonlinear Least Squares
We want so as to minimize as
We can achieve that if
solve for where
Options:
- Steepest descent:
- Gauss-Newton direction: 1
- Levenberg–Marquardt direction:
Dimensions
and ,
,
,
Assume has rank
If then
If then
Compute using a singular value decomposition of
Aside: Supervised Machine Learning
Suppose we have data in the form of pairs
We believe that the model is of the form
A standard approach is to find the values of , by solving where
This is a nonlinear least-square problem.
However, are parameters and we are searching for ; opposite of previous slides
Nonlinear Least Squares
Residual (or error): Loss: Mean Square Error:
Where is the Jacobian
is the Hessian
Dimensions
and ,
,
,
Assume has rank
If then
If then
Compute using a singular value decomposition of
Solutions
Global minimizer
A point is a global minimizer if 1 for all .
Local minimizer
A point is a local minimizer if there is a neighborhood of where for all , where a neighborhood of is an open set containing .
Strict local minimizer
A point is a strict local minimizer if there is a neighborhood of where for all with .
Summary
| Condition | What we know | What it tells us | Notes |
|---|---|---|---|
| 1st Ord Necessary | is LM1, differentiable | Proof justifies steepest descent | |
| 2nd Ord Necessary | is LM, and exist, are continuous on | and is PSD | |
| 2nd Ord Sufficient | and is PD | is strict LM | Leads to algorithms for finding LMs |
| 1st Ord Sufficient | is convex, is LM | is GM2 | |
| 1st Ord Sufficient | is convex, differentiable, | is GM | Leads to effective algorithms for finding global minima |
Overview of Algorithms
- Recall that the algorithms are iterative
- We need a starting point
- … and a method to produce iterates , ,
- Generally two methods:
- Line Search
- Trust Region
Note
The words method and algorithm are used interchangeably
Line Search Methods
- The algorithm chooses a direction
- Then, minimize on the line defined by . That is, solve
- In practice choose an that makes , not solve Equation 1.
- Practical method uses back-tracking line search to pick given
Line Search Methods
- Two common choices for directions.
- Negative gradient (steepest descent)
- Newton direction:
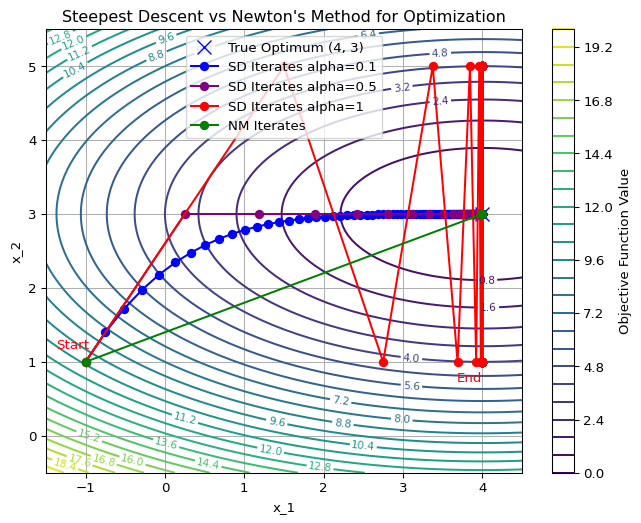
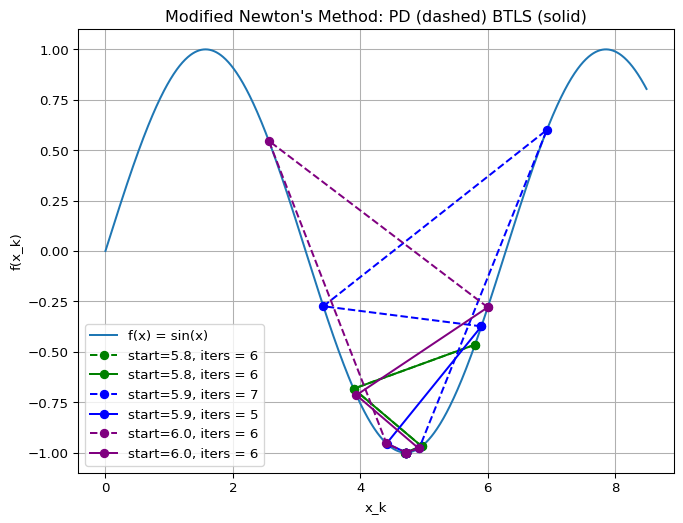
Example: Line Search Algorithms
Important
Newton’s method is not always better
Plotting Code
import numpy as np
import matplotlib.pyplot as plt
# Define the objective function and its gradient and Hessian
def f(x, y):
return #<answer>
def grad_f(x, y):
"""Gradient of f"""
return np.array()
def hess_f(x, y):
"""Hessian of f"""
return np.array()
# Steepest Descent
def steepest_descent(start, alpha=0.1,tol=1e-6, max_iter=50):
# your code
return x, iterates
# Plotting
x = np.linspace(-1, 4, 100)
y = np.linspace(-1, 5, 100)
X, Y = np.meshgrid(x, y)
Z = f(X, Y)
plt.figure(figsize=(8, 6))
# Contour plot of the objective function
contour = plt.contour(X, Y, Z, levels=30, cmap="viridis")
plt.clabel(contour, inline=True, fontsize=8)
plt.colorbar(contour, label="Objective Function Value")
plt.plot(4, 3, 'x', color="blue", markersize=10, label="True Optimum (4, 3)")
# Run Steepest Descent
start_point = [-1.0, 1.0]
optimum, iterates = steepest_descent(start_point)
# Extract iterate points for plotting
iterates = np.array(iterates)
x_iterates, y_iterates = iterates[:, 0], iterates[:, 1]
plt.plot(x_iterates, y_iterates, 'o-', color="blue", label="SD Iterates alpha=0.1")
# Annotate start and end points
plt.annotate("Start", (x_iterates[0], y_iterates[0]), textcoords="offset points", xytext=(-10, 10), ha="center", color="red")
plt.annotate("End", (x_iterates[-1], y_iterates[-1]), textcoords="offset points", xytext=(-10, -15), ha="center", color="red")
# Labels and legend
plt.xlabel("x_1")
plt.ylabel("x_2")
plt.title("Steepest Descent vs Newton's Method for Optimization")
plt.legend()
plt.grid(True)
plt.show()Trust Region Methods
- Approximate near using a model function
- Minimize near by solving
- Common choice: local quadratic Taylor series, with a spherical trust region
(trust-region Newton’s method)
Line Search and Trust Region Methods
In some cases, the two methods overlap 1 yields
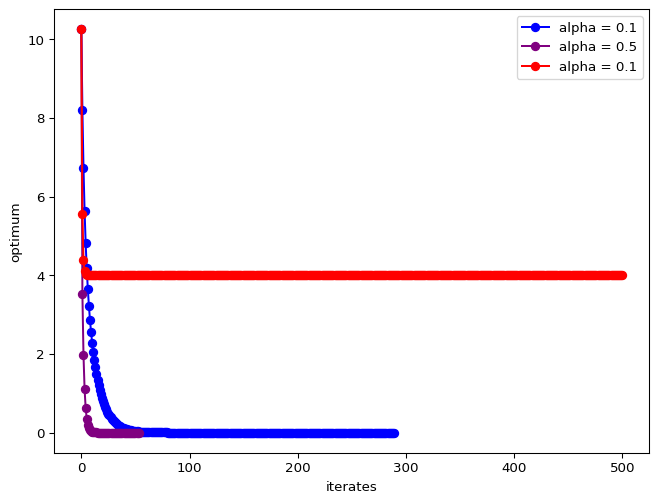
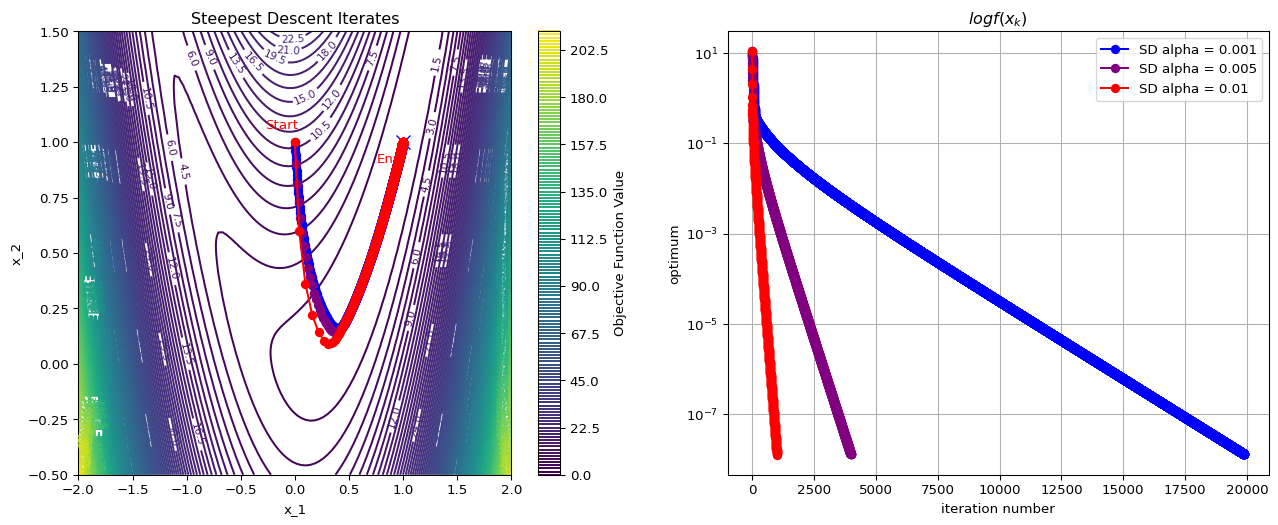
Exercise: Steepest Descent
The optimum is at . Test the behavior of steepest descent algorithms with various constant values of , starting from .
Solution
Step size selection
Recap
- In Unconstrained Optimization we saw theory that suggests algorithms:
- In proof of First Order Necessary Conditions, we saw that choosing and implies
- However, decreasing does not imply we reach the optimum if the decrease is too small
- Another strategy from the Sufficient Conditions is to solve
- In proof of First Order Necessary Conditions, we saw that choosing and implies
- Now we look at rules for and in an algorithm that will
- decrease enough so that
- we solve
Lipschitz Function
A function is Lipschitz on a set if for any
For twice differentiable functions, being differentiable is equivalent to for all
Steepest Descent
Descent Lemma
Let be a twice differentiable function whose gradient is Lipschitz continuous over some convex set . Then, for all , by Taylor’s Theorem,
This Lemma says that we can define a local quadratic function that is an upper bound for near a point .
If and , we get
- If , then .
- approaches zero only when
Example
To ensure decrease, we need
If , then
If , then
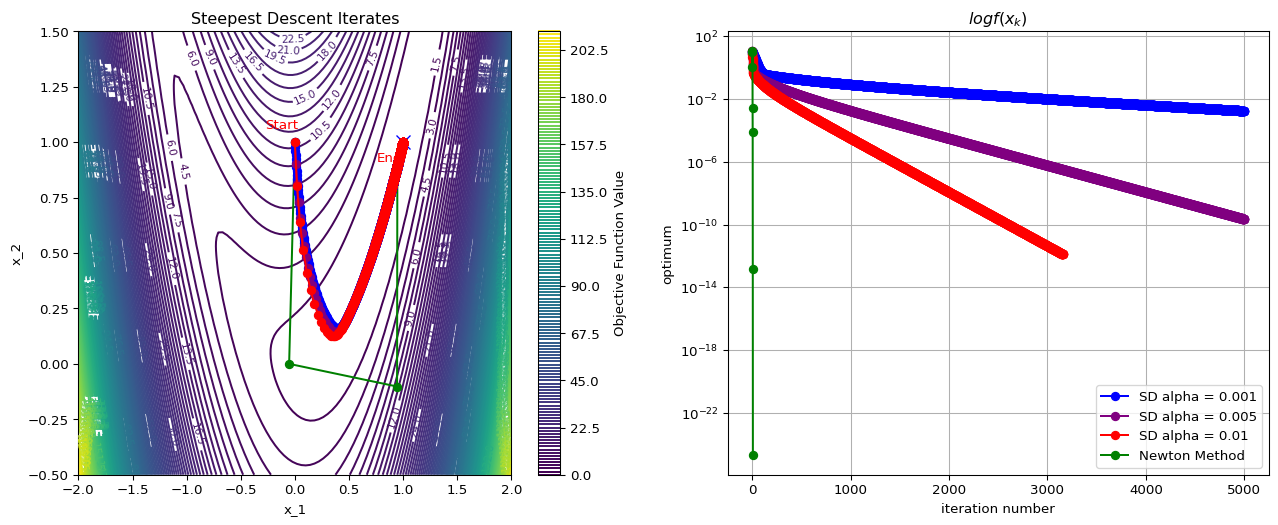
Rosenbrock Function
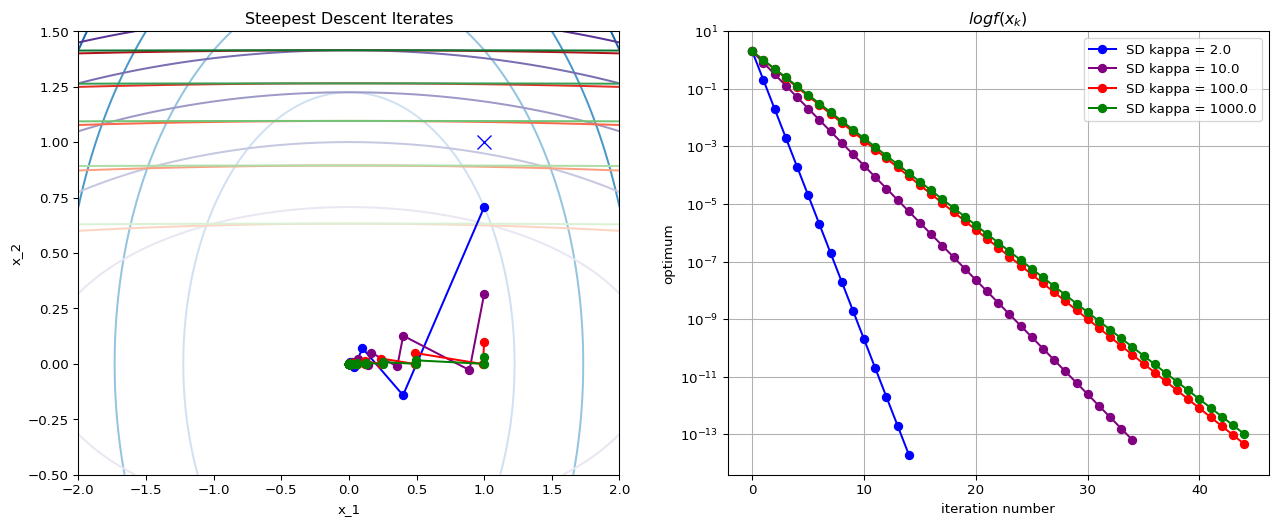
Condition Number
Newton’s Method
Motivation
We know that whatever point we are looking must be a stationary one, it must satisfy .
Newton’s method applies the Newton root-finding algorithm to :
- To solve , iteratively solve 1
Apply root finding to :
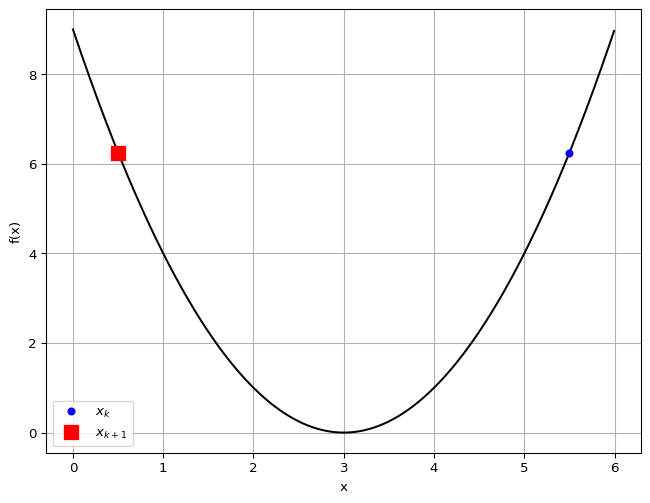
Example
- We want to find the minimizer of
- We want an accuracy of , i.e., stop when
- We compute
Alternate Motivation
When , we are minimizing the quadratic approximation which need not have minimum at
Example: Quadratic Function
Consider where
What happens when ?
Example: Rosenbrock Function
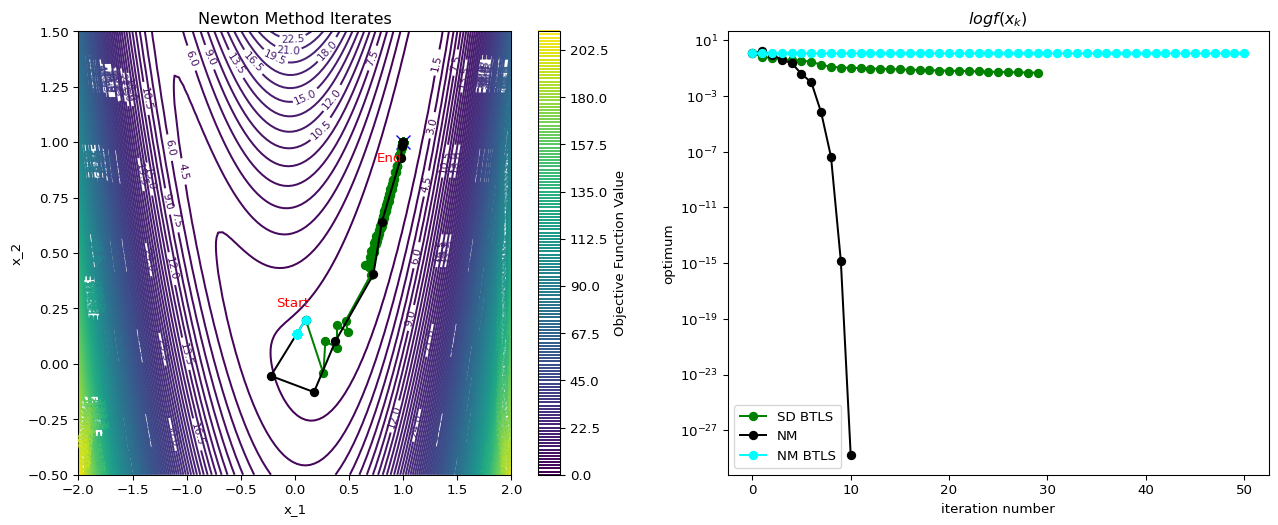
Convergence Rate
Theorem 3.5
Suppose that is twice differentiable and that the Hessian is Lipschitz continuous in a neighborhood of a solution at which the sufficient conditions are satisfied. Consider the iteration where . Then
- If is sufficiently close to , then
- The rate of convergence is quadratic
- The sequence of gradient norms converges quadratically to zero
Newton’s Revenge
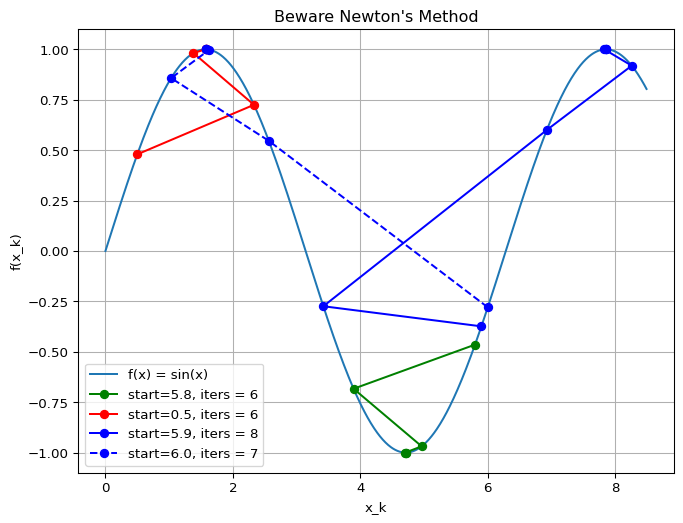
Modifications
Although Newton’s method is very attractive in terms of its convergence properties the solution, it requires modification before it can be used at points that are far from the solution.
The following modifications are typically used:
- Step-size reduction (damping)
- Modifying Hessian to be positive definite
- Approximation of Hessian
Damping
A search parameter is introduced where is selected to minimize .
A popular selection method is backtracking line search.
Positive Definiteness and Scaling
General class of algorithms is given by
- SD: , Newton: .
For small , it can be shown that
- As , the second term on the rhs dominates the third.
- To guarantee a decrease in , we must have .
- Simplest way to ensure this is to require .
Positive Definiteness and Scaling
In practice, Newton’s method must be modified to accommodate the possible non-positive definiteness of at regions far from the solution.
Common approach: for some .
This can be regarded as a compromise between SD ( very large) and Newton’s method ().
Levenberg-Marquardt performs Cholesky factorization for a given value of as follows
This factorization checks implicitly for positive definiteness.
If the factorization fails (matrix not PD) is increased.
Step direction is found by solving .
Newton’s Revenge Avenged
Nonlinear Least Squares: Localization Example
Problem Definition
Range-Based Localization: Find position given noisy range measurements to known beacons.
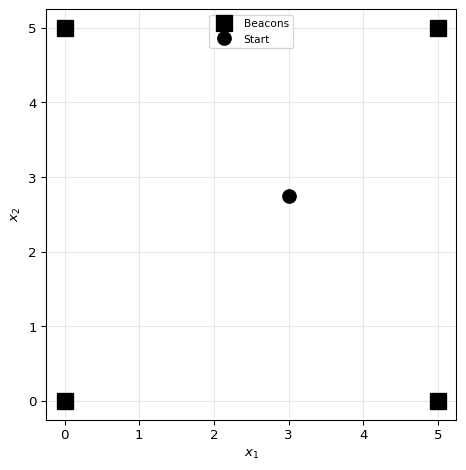
Problem Definition
Range-Based Localization: Find position given noisy range measurements to known beacons.
Given:
- Beacon positions
- Measured distances
Residuals:
Objective:
Jacobian: Row is
This is a unit vector pointing from beacon toward .
This is a common robotics problem: GPS, UWB localization, acoustic positioning
Algorithm Comparison
Three methods to solve :
| Method | Update Rule | Direction |
|---|---|---|
| Gradient Descent | Steepest descent on | |
| Gauss-Newton | Newton with | |
| Levenberg-Marquardt | Damped Gauss-Newton |
Key Insights:
- GN approximates Hessian as , ignoring second-order residual terms
- LM blends GD (large ) and GN (small ) via damping parameter
- Adaptive : increase when step rejected, decrease when accepted
Code: Localization Example
Show setup code
import numpy as np
import matplotlib.pyplot as plt
# Generate noisy measurements
np.random.seed(42)
noise_std = 0.1
true_distances = np.linalg.norm(beacons - true_pos, axis=1)
measured_distances = true_distances + np.random.randn(4) * noise_std
def residuals(x):
"""Compute residual vector e(x) = ||x - b_i|| - d_i"""
return np.linalg.norm(beacons - x, axis=1) - measured_distances
def jacobian(x):
"""Compute Jacobian matrix J(x) where J_i = (x - b_i)^T / ||x - b_i||"""
J = np.zeros((4, 2))
for i, b in enumerate(beacons):
diff = x - b
norm = np.linalg.norm(diff)
if norm > 1e-10:
J[i] = diff / norm
return J
def cost(x):
"""Compute sum of squared residuals"""
e = residuals(x)
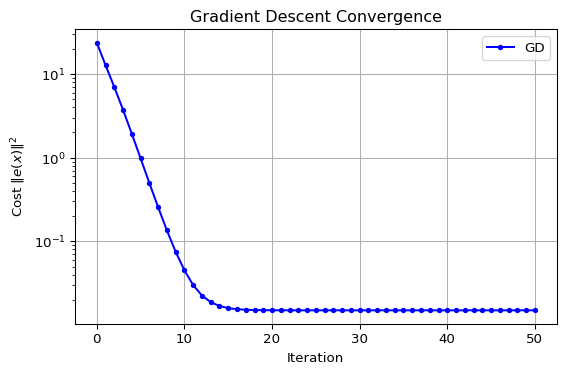
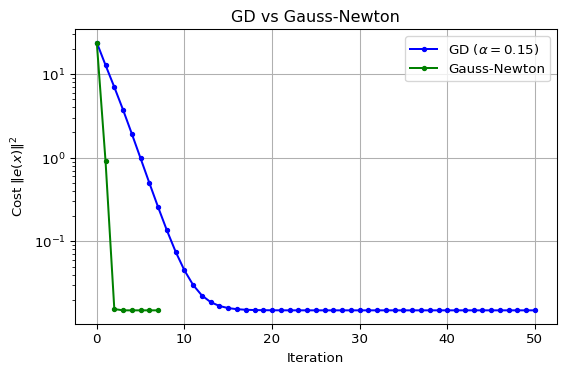
return np.sum(e**2)Gradient Descent for NLS
Update:
- Direction is gradient of
- Requires step size selection
- Slow but reliable convergence
Gauss-Newton Method
Update:
- Solves linear system
- No step size needed (full step)
- Fast quadratic convergence near solution
Levenberg-Marquardt Method
Update:
- Adaptive : blend GD and GN
- Large gradient descent (robust)
- Small Gauss-Newton (fast)
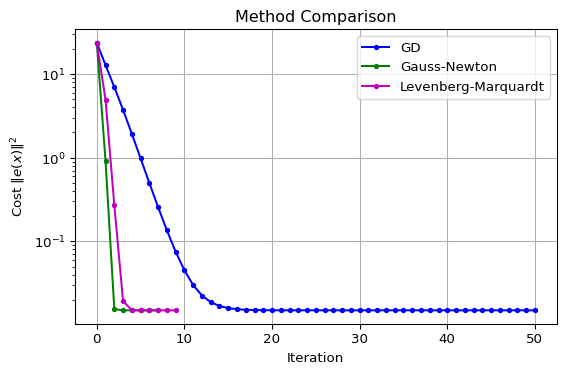
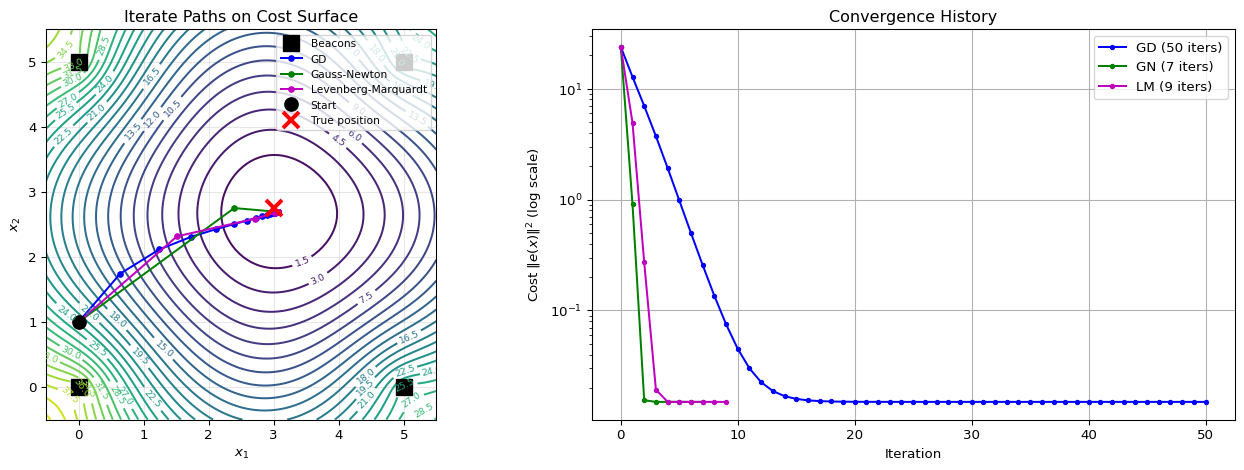
Visualization: Iterate Paths
Results Discussion
Observations:
| Method | Iterations | Convergence |
|---|---|---|
| Gradient Descent | Many (~50) | Linear rate |
| Gauss-Newton | Few (~5) | Quadratic near solution |
| Levenberg-Marquardt | Few (~5) | Adaptive, robust |
Key Takeaways:
- GD: Slow but reliable, many iterations
- GN: Fast quadratic convergence, may fail far from solution
- LM: Best of both worlds
- Large GD-like (robust)
- Small GN-like (fast)
When to use which?
- GD: When Jacobian is expensive or problem is poorly conditioned
- GN: Well-posed problems with good initial guess
- LM: Default choice for most NLS problems
Summary
Summary
You can now minimize (when unconstrained) iteratively. Find LM by
- Choosing direction
- Steepest descent with constant step size is easy and reliable but slow
- Newton method is fast but expensive and unreliable
- needs modifications for reliable convergence
- Quasi-newton methods are a balance, but tricky
- Choosing step size
- Back-tracking for SD and modified NM improves performance
- Strong Wolfe conditions for Quasi-newton methods
- Not tackled: constraints, expensive /, discrete , non-smooth
From Systems Optimization I • ME 676 Home