Proximal Policy Optimization
PPO: Model-Free Reinforcement Learning
Instructor: Hasan A. Poonawala
Mechanical and Aerospace Engineering
University of Kentucky, Lexington, KY, USA
Topics:
Bridge from MPPI
Policy gradient theorem
Importance sampling & trust regions
Clipped surrogate objective
Advantage estimation
Algorithm and properties
A Progression in Optimal Control
Each method relaxes one key assumption of the previous.
| Method | Dynamics | Key relaxation |
|---|---|---|
| LQR | linear | baseline: analytical solution |
| iLQR | nonlinear | drop linearity via local linearization |
| MPC | nonlinear | drop infinite horizon; add constraints; replan online |
| MPPI | nonlinear | drop differentiability; use sampling |
| PPO | unknown | drop the model entirely; learn from interaction |
Every method above requires a access to a dynamics model . PPO removes that requirement.
From MPPI to PPO
MPPI
MPPI moves through these distributions in each planning step:
The parameter being optimized is — the mean of the control distribution — a fixed sequence of vectors.
The update is a cost-weighted mean:
The optimized object is an open-loop control sequence: it does not depend on state encountered during execution.
PPO
PPO inserts an additional level — a parameterized state-dependent policy:
The parameter being optimized is — the weights of a neural network (or other function approximator) that maps any state to a distribution over actions.
The update adjusts so that actions leading to higher reward become more probable.
| MPPI | PPO | |
|---|---|---|
| Optimized object | control sequence | policy params |
| Action at runtime | fixed per step | |
| Feedback | open-loop (replanned each cycle) | closed-loop (state-dependent) |
| Dynamics model | required | not required |
The Bridge: Same Core Mechanism
Despite the structural difference, MPPI and PPO share the same core update principle:
Sample trajectories under the current distribution.
Weight samples by reward (or advantage).
Update the parameter toward the higher-weight samples.
The proximal constraint in PPO plays the same role as the KL penalty in MPPI’s information-theoretic derivation: both prevent the update from stepping so far from the current distribution that the importance weights become unreliable.
| MPPI | PPO |
|---|---|
| 1 | |
| KL term limits policy change | clipping limits policy change |
Policy Gradient Setup
The Reinforcement Learning Objective
An agent interacts with an environment: at each step it observes state , takes action , and receives reward .
Goal: find to maximize expected discounted return:
where is a discount factor and .
Unlike MPPI, no dynamics model appears. The reward signal arrives directly from the environment. The only requirement is that is differentiable in .
Reinforcement Learning uses an estimated value function or -Value to summarize what will happen, instead of an explicit model .
Value Functions and Advantage
Define:
the state-value function — expected return from state under policy .
the action-value function — expected return after taking action in state .
the advantage — how much better (or worse) action is than the average action from state .
: this action is better than average — make it more probable. : worse than average — make it less probable.
Advantages as shortcuts
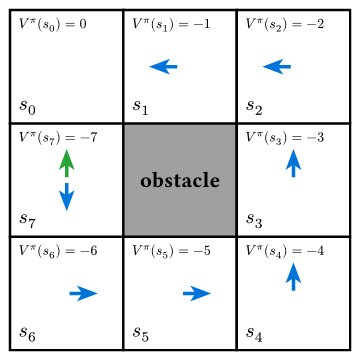
for all states except .
So, under blue policy,
Stochastic Policy
A simple and commonly used stochastic state-dependent policy is Gaussian:
- is a state-dependent ‘mean action’.
Example: at meters average force is N to push a box back to - is independent of and to simplify computations
Policy Gradient Theorem
The gradient of with respect to is:
This is the policy gradient theorem (PGT). Key observations:
- Only needs to be differentiable — the environment dynamics need not be.
- : direction in -space that increases the probability of at .
- Brings closer to , increasing probability of action
- Multiplied by : More rewards imply greater increase in probability of that action relative to others
Algorithms using PGT
REINFORCE: Simulate using stochastic actions, implement PGT as-is using actual rewards
Vanilla policy gradient: Remove a baseline from actual rewards. Usually . Why: reduces variance without introducing any bias
Actor-Critic: Use a critic function to estimate , not actual rewards. A popular critic is the advantage function.
Probability of better actions () increases while that of worse actions () decreases
Why Actor-Critic Is Unstable
Actor-Critic methods work in principle but fails in practice due to step-size sensitivity:
- Too small a step → slow convergence, wasted samples
- Too large a step → the policy changes drastically, old samples are no longer representative, and the update may push into a region from which recovery is difficult
The fundamental issue: gradient ascent in -space does not respect the geometry of the probability distribution . A small step in can produce a large change in .
TRPO (Trust Region Policy Optimization) solved this by constraining , but it requires second-order optimization (conjugate gradient + line search) — expensive.
PPO achieves similar stability with a simple first-order trick: clip the importance ratio.
The PPO Objective
Importance Sampling Enters
Suppose we collected data under . We want to optimize using those samples — this is importance sampling.
Define the probability ratio:
Then the policy gradient objective can be written as:
This is exactly the importance-sampling reweighting from MPPI: we collected samples under (analogous to ), and reweight by (analogous to ) to estimate expectations under the new distribution.
Problem: comes from . Unconstrained maximization of can push to extreme values. If moves far from ( far from ), the associated gradient is unreliable and the update collapses.
The Clipped Surrogate Objective
PPO replaces with a clipped version:
where is a small hyperparameter.
Intuition for the clip:
When , the gradient of the clipped term w.r.t is zero, no update when the probabilities have changed too much going from .
Intuition for the min:
Makes the clipping asymmetric: only clip when
- and new probability under is already much higher at current
- and new probability under is already much lower at current
Clipping prevents the policy from taking greedy steps that move it outside the region where the current samples are informative — the same motivation as the KL term in MPPI.
Advantage Estimation
Estimating in Practice
The true advantage is unknown. Two practical estimators:
Monte Carlo return:
Unbiased but high variance — a single sampled return can be far from the mean.
TD residual (1-step):
Low variance but biased if is inaccurate.
Generalized Advantage Estimation (GAE): interpolate with parameter :
: pure TD (low variance, more bias); : Monte Carlo (unbiased, high variance).
The Critic: Learning
PPO jointly trains two networks (or one with two heads):
Actor : the policy — updated via .
Critic : the value function — updated by minimizing the TD error:
The full PPO loss also includes an entropy bonus to encourage exploration:
There is no equivalent of the critic in MPPI — MPPI uses the raw trajectory cost directly rather than learning a value function from data.
The Algorithm
PPO
Input: policy π_θ, value network V_φ, clip ε, rollout length T, epochs K
Repeat until convergence:
1. Collect rollout:
For t = 0 to T-1:
a_t ~ π_θ(· | s_t), step environment, observe r_t, s_{t+1}
2. Compute advantages and target values:
δ_t = r_t + γ V_φ(s_{t+1}) − V_φ(s_t)
Â_t = GAE(δ_0:T, λ̂) (generalized advantage estimate)
V̂_t = Â_t + V_φ(s_t) (target for critic)
3. Save old policy: θ_old ← θ
4. Optimize for K epochs over the collected batch:
For each minibatch (s_t, a_t, Â_t, V̂_t):
r_t(θ) = π_θ(a_t | s_t) / π_{θ_old}(a_t | s_t)
L^CLIP = mean[ min( r_t Â_t, clip(r_t, 1−ε, 1+ε) Â_t ) ]
L^VF = mean[ (V_φ(s_t) − V̂_t)² ]
L^H = mean[ H(π_θ(· | s_t)) ] (entropy bonus)
Update θ, φ by gradient ascent on L^CLIP − c₁ L^VF + c₂ L^H
5. Repeat from step 1.Steps 1–2 collect experience; step 4 reuses it for multiple gradient updates (multiple epochs over the same batch), which is more sample-efficient than one-step REINFORCE. The clip makes multi-epoch reuse safe.
What PPO Gives You
| Property | Explanation |
|---|---|
| Model-free | No dynamics model needed; learns purely from tuples |
| Closed-loop | Policy adapts to any visited state |
| Stable updates | Clipping prevents destructive large steps; robust to learning rate |
| Sample reuse | Multiple gradient epochs per rollout batch |
| Continuous or discrete actions | Gaussian policy for continuous; softmax for discrete |
| GPU-friendly | Parallel environment rollouts; batch backprop through the network |
What PPO still requires: enough environment interactions to learn a good value function and policy. Sample efficiency is better than REINFORCE but far lower than model-based methods like MPPI. PPO may need millions of environment steps for complex tasks.
Hyperparameters
| Parameter | Effect | Typical value |
|---|---|---|
| (clip range) | Larger → more aggressive update | 0.1–0.3 |
| (rollout length) | Longer → better return estimates | 128–4096 steps |
| (update epochs) | More → better use of each batch | 3–10 |
| (GAE) | Bias-variance tradeoff in advantage | 0.95 |
| (discount) | Effective planning horizon | 0.99 |
| (loss weights) | Value vs. entropy tradeoff | , |
PPO is often described as the “default” deep RL algorithm because its performance is robust across a wide range of hyperparameter settings — the clip replaces careful learning-rate tuning.
MPPI vs. PPO
| MPPI | PPO | |
|---|---|---|
| Dynamics model | Required (must simulate ) | Not required |
| Control structure | Open-loop sequence | Closed-loop policy |
| Distribution chain | noise → control → trajectory → cost | → policy → action → trajectory → reward |
| Optimization object | Control mean | Policy params |
| “Proximity” mechanism | KL penalty | Ratio clip |
| Sample efficiency | High (model-based) | Lower (model-free) |
RL Algorithm Landscape
Taxonomy of Key Algorithms
| Algorithm | Policy | On/Off-policy | Action space | Needs critic | Key mechanism |
|---|---|---|---|---|---|
| REINFORCE | stochastic | on | discrete / cont. | no | Monte Carlo returns |
| A2C / A3C | stochastic | on | discrete / cont. | yes () | parallel workers + TD advantage |
| PPO | stochastic | on | discrete / cont. | yes () | clipped IS ratio; multi-epoch reuse |
| TD3 | deterministic | off | continuous | yes (twin ) | fixes DDPG overestimation |
| SAC | stochastic | off | continuous† | yes (twin ) | entropy regularization; max-entropy framework |
†Discrete SAC exists but is less common.
On-policy algorithms discard data after each update — samples must come from the current policy. Off-policy algorithms store data in a replay buffer and can reuse old transitions, making them more sample-efficient but harder to stabilize.
Choosing an Algorithm
Action space drives the first cut:
- Discrete actions (game buttons, token selection): REINFORCE, A2C, PPO
- Continuous actions (joint torques, velocities): PPO, TD3, SAC, DDPG
Sample budget drives the second cut:
- Data is cheap (fast simulator, parallelizable): on-policy methods (PPO, ACKTR) are simpler and competitive
- Data is expensive (real hardware, slow sim): off-policy methods (SAC, TD3) extract more from each transition
Optimal Control • ME 676 Home