Motivation
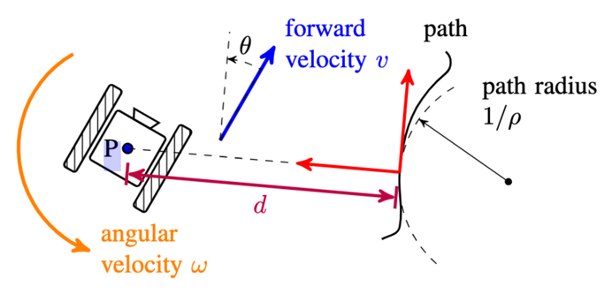
Most path-following controllers need a relative path state for feedback to assure convergence to the path. This relative path state is typically the relative heading to the path and the distance of the robot to the nearest point on the path. Extracting such a position from sensor readings is an expensive affair in general. However, using direct feedback from high-dimensional sensors becomes difficult to trust, since there are usually no guarantees.
Challenge
An end-to-end controller that avoids states is great for implementation, but then closed-loop analysis becomes difficult without a connection to a motion (dynamics) model. Most work tries to create this connection by learning a sensor model that predicts the image (and therefore the control) in a given (relative path) state. The issue is that there is no guarantee that the same image will be obtained in the same relative position to a path. This approach cannot work outside of highly structured environments.
Main Idea
Our idea is to design a structured controller that works by mapping the image down to a scalar number, called a sensor-based score function, which is in turn mapped into robot motion commands. As the robot moves, it sees different images, producing different scores, in a feedback loop. We show that the specific score value is generally not important to guarantee path following. As long as it changes monotonically with the relative path variables, and is nearly zero when the robot is on the path and aligned with it, then the robot will follow the path and come back to it when disturbed. Our key contribution is that the conditions on the score function are very limited, and specifically, they don’t rely on obtaining a specific image in a specific state. Loosely speaking, the score function doesn’t need to predict specific values, it only needs to have the right shape. This is a far more robust and flexible requirement.
Significance Of Our Approach: Tackling Distribution Shift
The sensor-based score function will usually come from some process of training, whether in simulation or the real world. This training is typically brittle to differences between the training and test environment. For a robot following a path, adding or removing an object in an environment might change the scores predicted at different locations because the resulting sensor readings have changed. However, our guarantees on path following are not invalidated just because these scores have changed, unlike for most similar work. The new scores often turn out to also be monotonic with respect to relative path state, so that the path-following controller still works. For data-driven or learned controllers, this property provides one way to mitigate the problem of distribution shift.
Ongoing Work
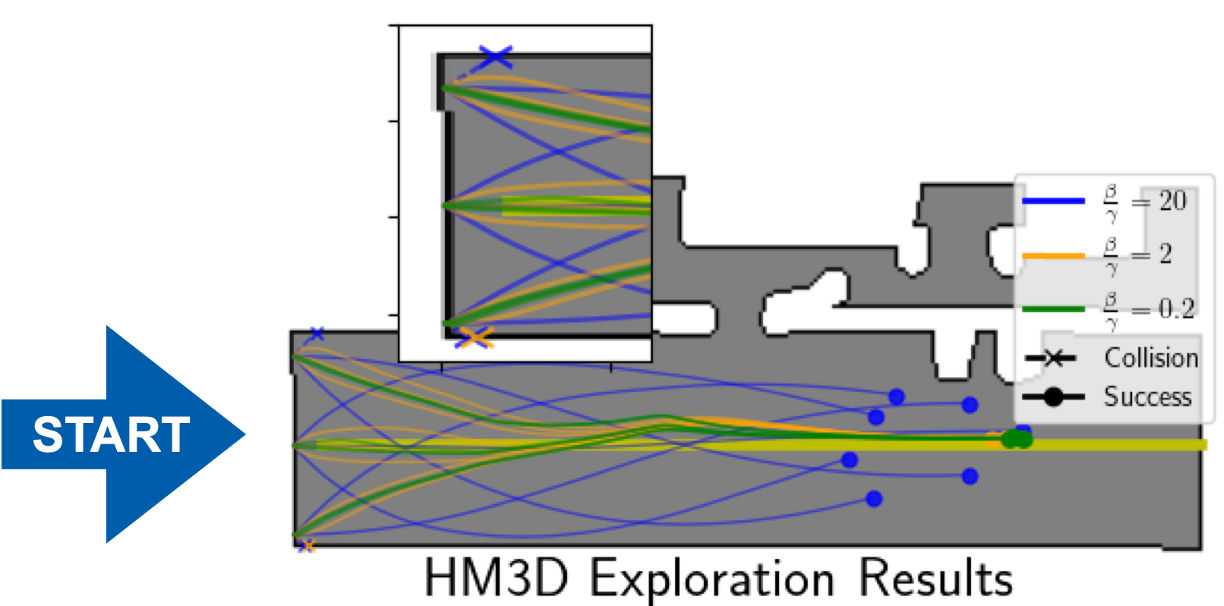
Our approach enables a robot to reliably follow a path without state estimation. Path-following is an important but ultimately low-level capability for general robot navigation. Our current work aims to integrate this path-following capability with mapping and planning algorithms for navigation.