ME/AER 647 Systems Optimization I
Line Search
Instructor: Hasan A. Poonawala
Mechanical and Aerospace Engineering
University of Kentucky, Lexington, KY, USA
Topics:
Wolfe Conditions
Backtracking Line Search
Convergence properties
Step size selection
Recap
- In Unconstrained Optimization we saw theory that suggests algorithms:
- In proof of First Order Necessary Conditions, we saw that choosing and implies
- However, decreasing does not imply we reach the optimum if the decrease is too small
- Another strategy from the Sufficient Conditions is to solve
- In proof of First Order Necessary Conditions, we saw that choosing and implies
- Now we look at rules for and in an algorithm that will
- decrease enough so that
- we solve
Lipschitz Function
A function is Lipschitz on a set if for any
For twice differentiable functions, being differentiable is equivalent to for all
Steepest Descent
Descent Lemma
Let be a twice differentiable function whose gradient is Lipschitz continuous over some convex set . Then, for all , by Taylor’s Theorem,
This Lemma says that we can define a local quadratic function that is an upper bound for near a point .
If and , we get
- If , then .
- approaches zero only when
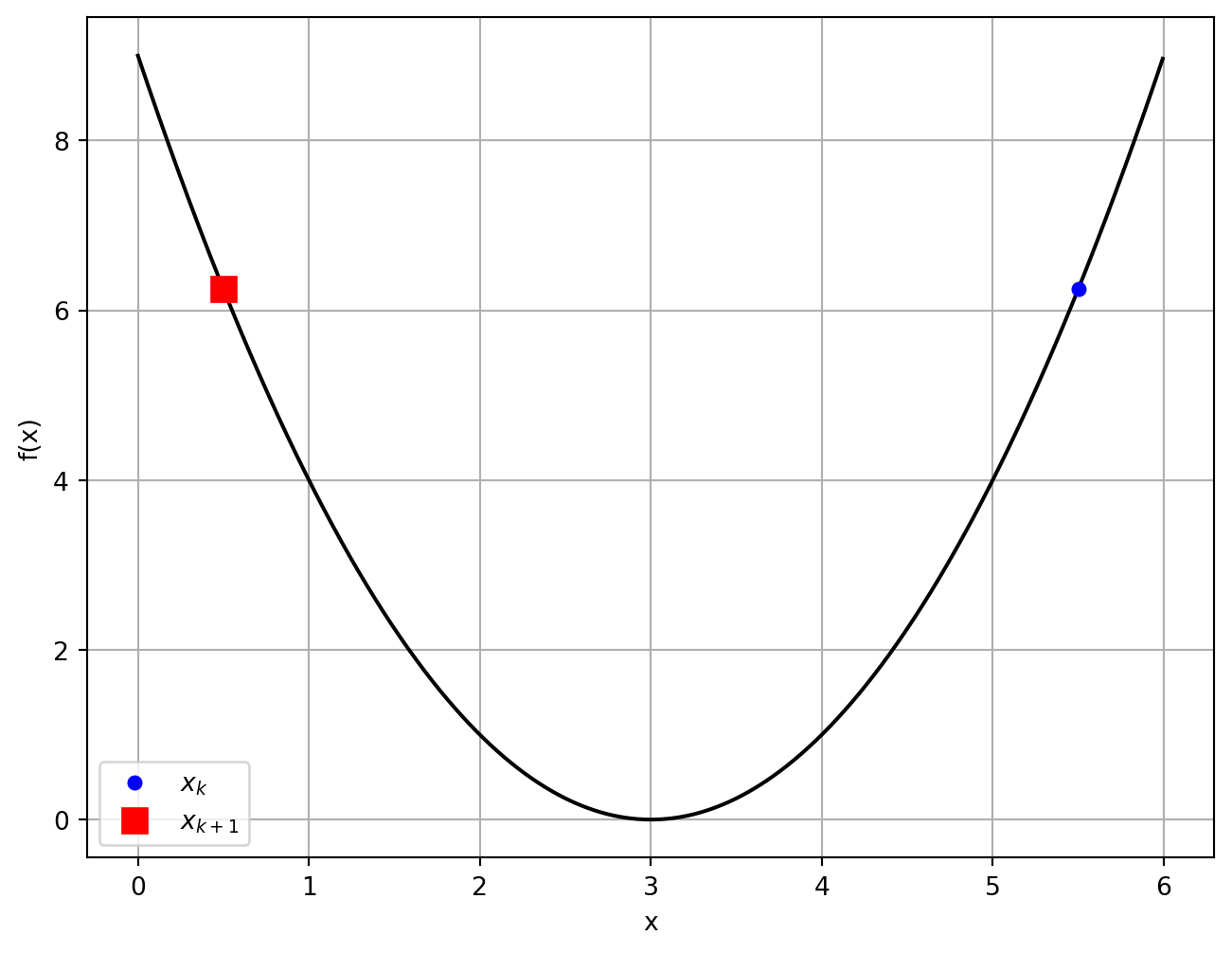
Example
To ensure decrease, we need
If , then
If , then
Optimal Steepest Descent
Descent Lemma:
The smallest bound on occurs when :
But what happens when we don’t know ?
- Start with small , check whether
- If not satisfied, double , repeat
This is a preview of backtracking
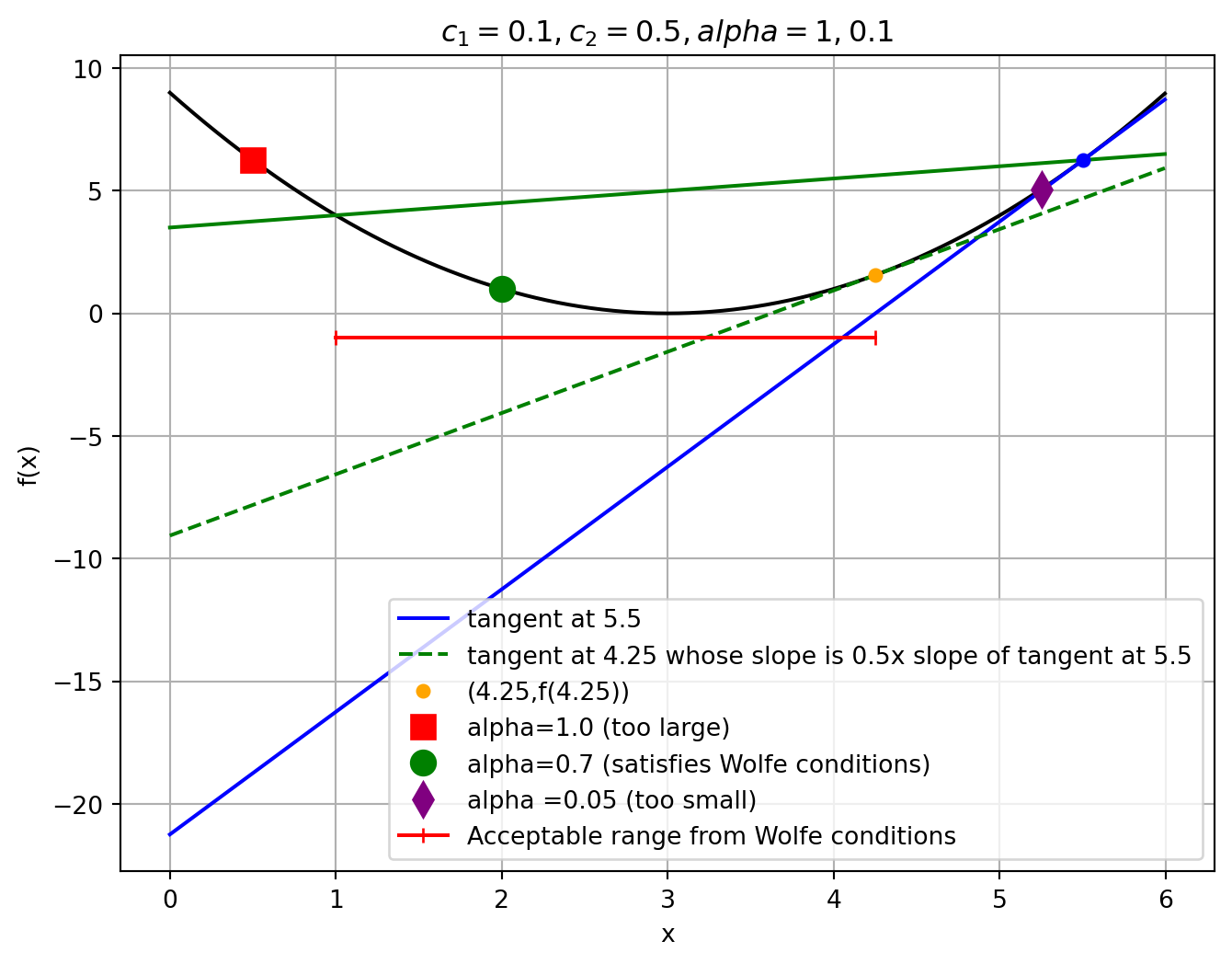
Wolfe Conditions
- Sufficient decrease condition (Armijo rule) on :
- Curvature condition on : with .
- The sufficient condition prevents large steps that don’t provide enough benefit
- Through a function that linearly links decrease in with size of
- The curvature condition prevents small steps that don’t provide enough benefit
- Through a sufficient change in
Example Wolfe Conditions
Backtracking
Replaces curvature condition with a reducing sequence of .
- Choose
- Initialize (start with large step)
- While
- (reduce if too large)
Example values: , ,
Backtracking Example
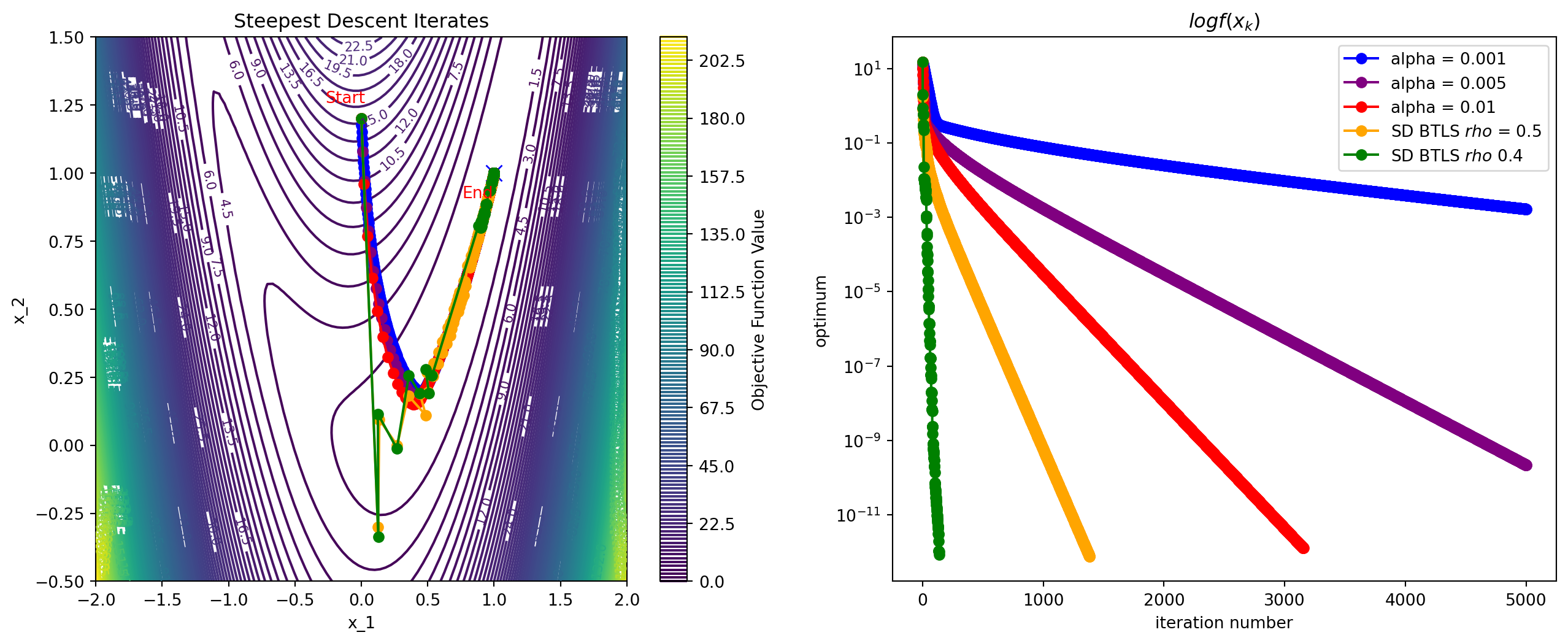
Convergence Analysis
Convergence
Informally
Will
Weaker
Will
Still weaker
Will
Zoutendijk Condition
- Involves the angle between steepest descent direction and chosen direction :
- If , then and
- If is , then but small
- If , then , and is not a strict descent direction
Theorem
Consider any iteration of the form , where is a descent direction and satisfies the Wolfe conditions. Suppose that is bounded below in and that is continuously differentiable in an open set containing the level set . Assume also that the gradient is Lipschitz continuous on , then
Convergence from Zoutendijk Condition
If we choose such that for all , then the Zoutendijk condition implies that
- If is positive definite with uniformly bounded condition number (), then for ,
- What algorithm does this conclusion apply to when or ?
Similar results apply to chosen using backtracking line search.
Convergence Rate
Informally
How fast does
Less informally
The convergence rate measures how fast the error in the solution decreases. The error can be in terms of the optimum , the optimal value , or .
Example
If for constant , then the convergence is linear. Moreover, the number of iterations .
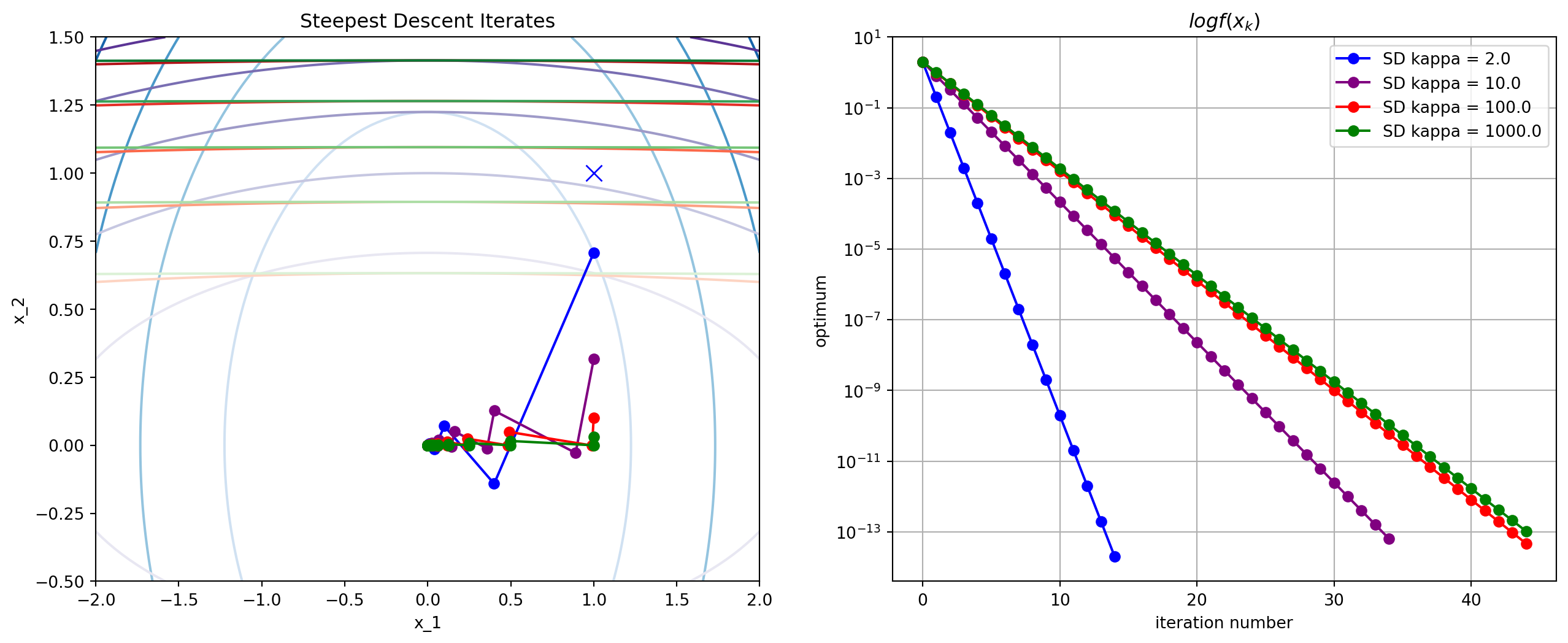
Convergence Rate of Steepest Descent with Exact Line Search
- When where , we get linear convergence in
- See Theorem 3.3: ,
- If condition number is , with and , after 1000 iterations, objective is only
- When is twice continuously differentiable, if where satisfies SOSC, then we get linear convergence in
- See Theorem 3.4
- If we use inexact line search, the convergence is even slower
Rosenbrock Function
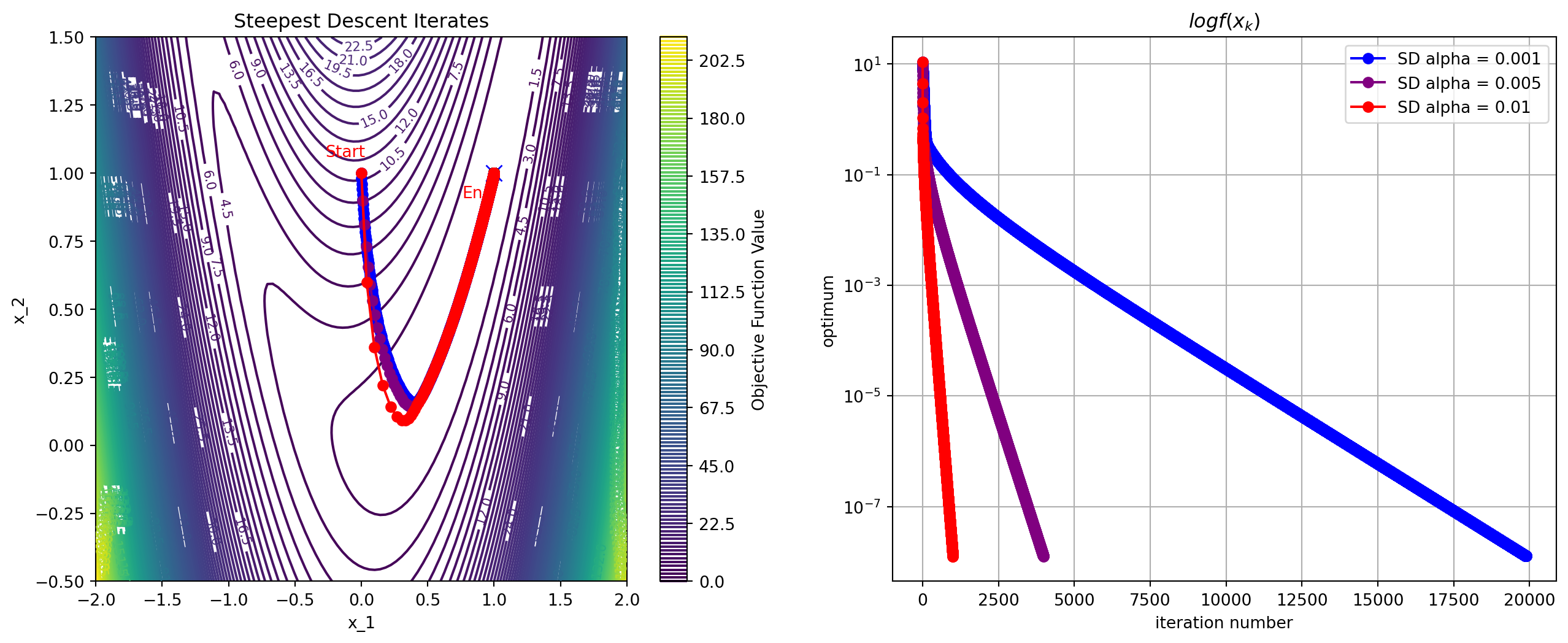
Condition Number
Newton’s Method
Motivation
We know that whatever point we are looking must be a stationary one, it must satisfy .
Newton’s method applies the Newton root-finding algorithm to :
- To solve , iteratively solve 1
Apply root finding to :
Example
- We want to find the minimizer of
- We want an accuracy of , i.e., stop when
- We compute
Alternate Motivation
When , we are minimizing the quadratic approximation which need not have minimum at
Example: Quadratic Function
Consider where
What happens when ?
Example: Rosenbrock Function
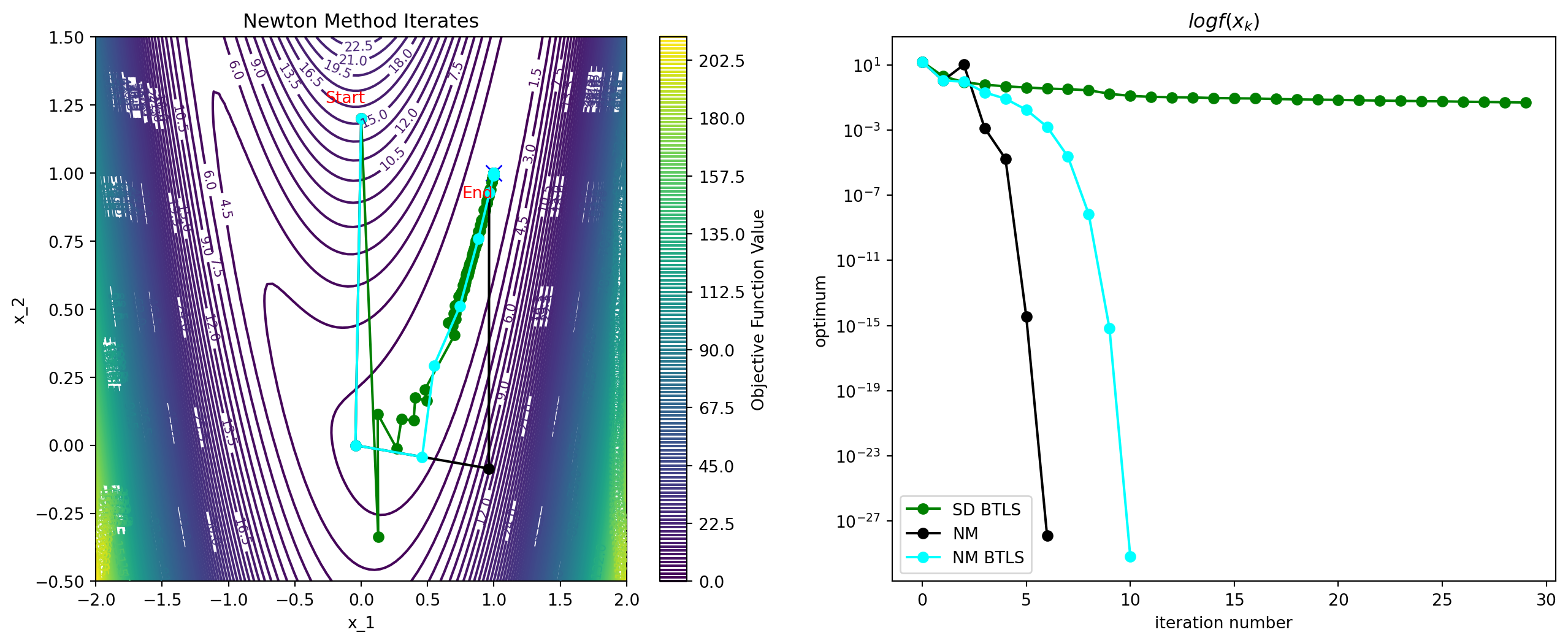
Convergence Rate
Theorem 3.5
Suppose that is twice differentiable and that the Hessian is Lipschitz continuous in a neighborhood of a solution at which the sufficient conditions are satisfied. Consider the iteration where . Then
- If is sufficiently close to , then
- The rate of convergence is quadratic
- The sequence of gradient norms converges quadratically to zero
Proof Outline
Here, we directly look at , using
Under the assumption that is -Lipschitz, using Taylor’s theorem, we have
For , we can rewrite this expression using
For , we can rewrite this expression using as
If , then we get quadratic convergence.
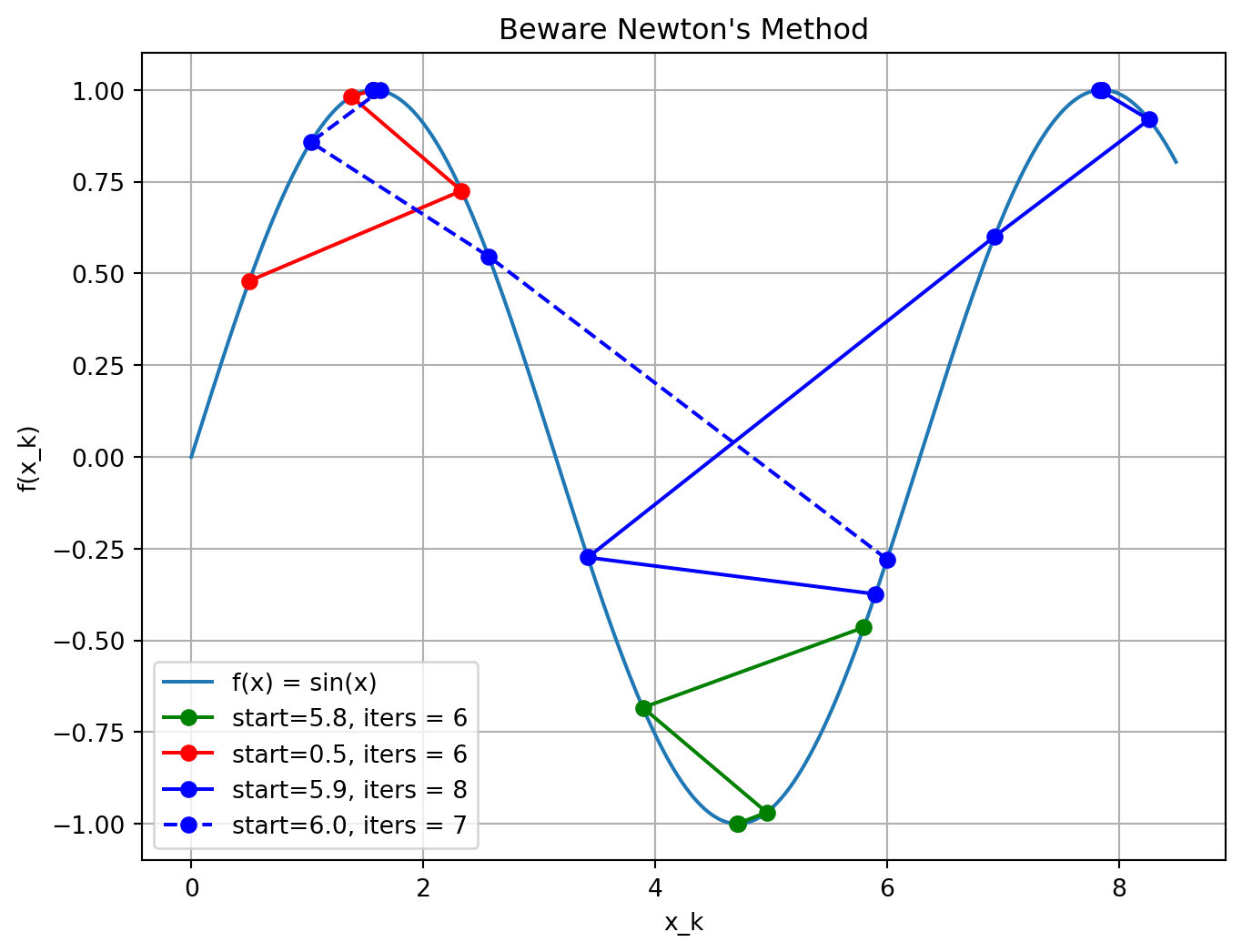
Newton’s Revenge
Modifications
Although Newton’s method is very attractive in terms of its convergence properties the solution, it requires modification before it can be used at points that are far from the solution.
The following modifications are typically used:
- Step-size reduction (damping)
- Modifying Hessian to be positive definite
- Approximation of Hessian
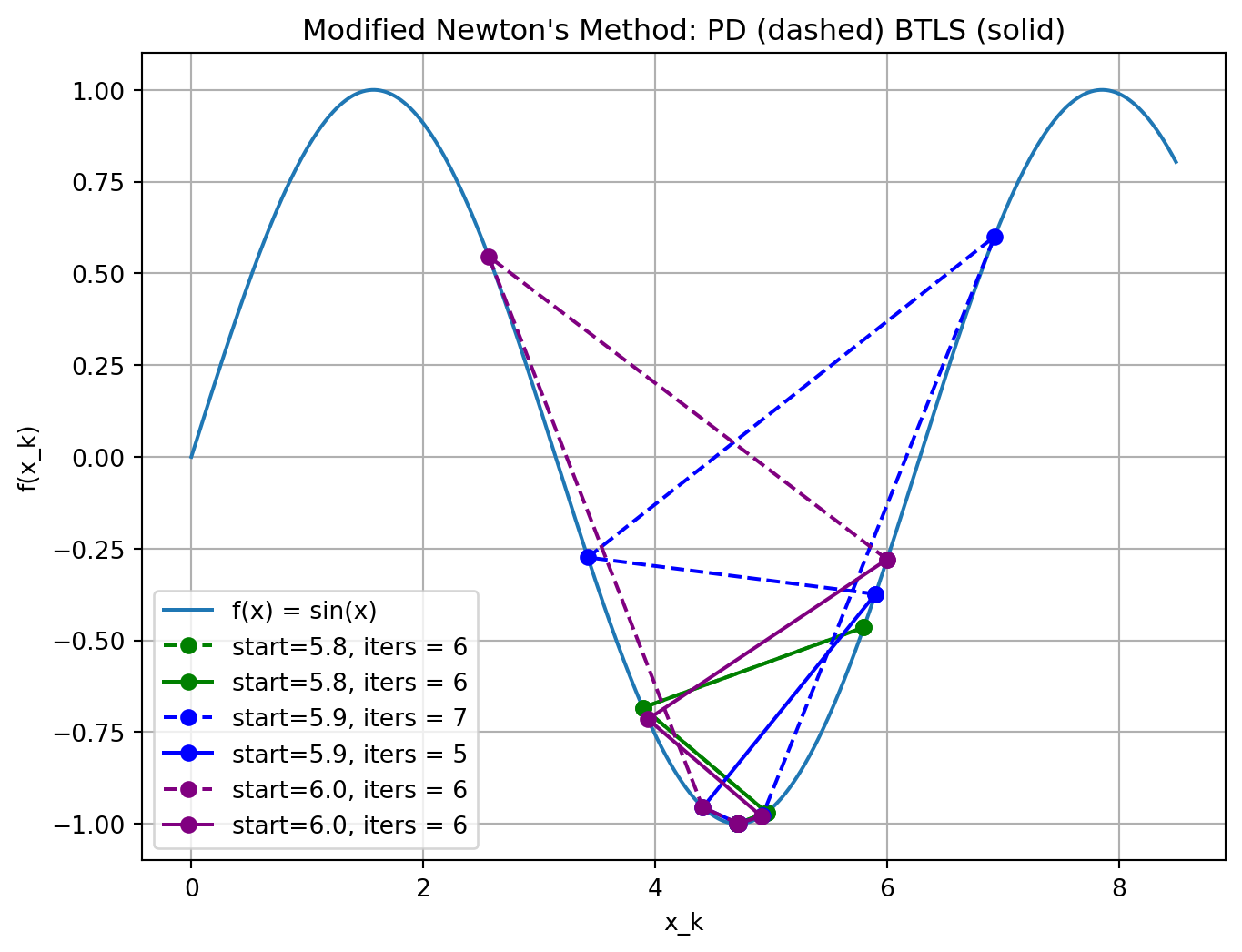
Damping
A search parameter is introduced where is selected to minimize .
A popular selection method is backtracking line search.
Positive Definiteness and Scaling
General class of algorithms is given by
- SD: , Newton: .
For small , it can be shown that
- As , the second term on the rhs dominates the third.
- To guarantee a decrease in , we must have .
- Simplest way to ensure this is to require .
Positive Definiteness and Scaling
In practice, Newton’s method must be modified to accommodate the possible non-positive definiteness of at regions far from the solution.
Common approach: for some .
This can be regarded as a compromise between SD ( very large) and Newton’s method ().
Levenberg-Marquardt performs Cholesky factorization for a given value of as follows
This factorization checks implicitly for positive definiteness.
If the factorization fails (matrix not PD) is increased.
Step direction is found by solving .
Newton’s Revenge Avenged
Quasi-Newton Method
Computes as a solution to the secant equation:
Then solve
One dimension
Quasi-Newton Method
Algorithms for updating :
Broyden, Fletcher, Goldfarb, and Shanno (BFGS):
Symmetric Rank-One (SR1):
Algorithms for updating :
Quasi-Newton Method: Details
Initialization: Start with
Step size: for all may interfere with approximating the Hessian
- Backtracking isn’t enough to choose good
- Choose to satisfy strong Wolfe conditions
- Details are very technical (numerical computing challenges)
Example: Rosenbrock Function
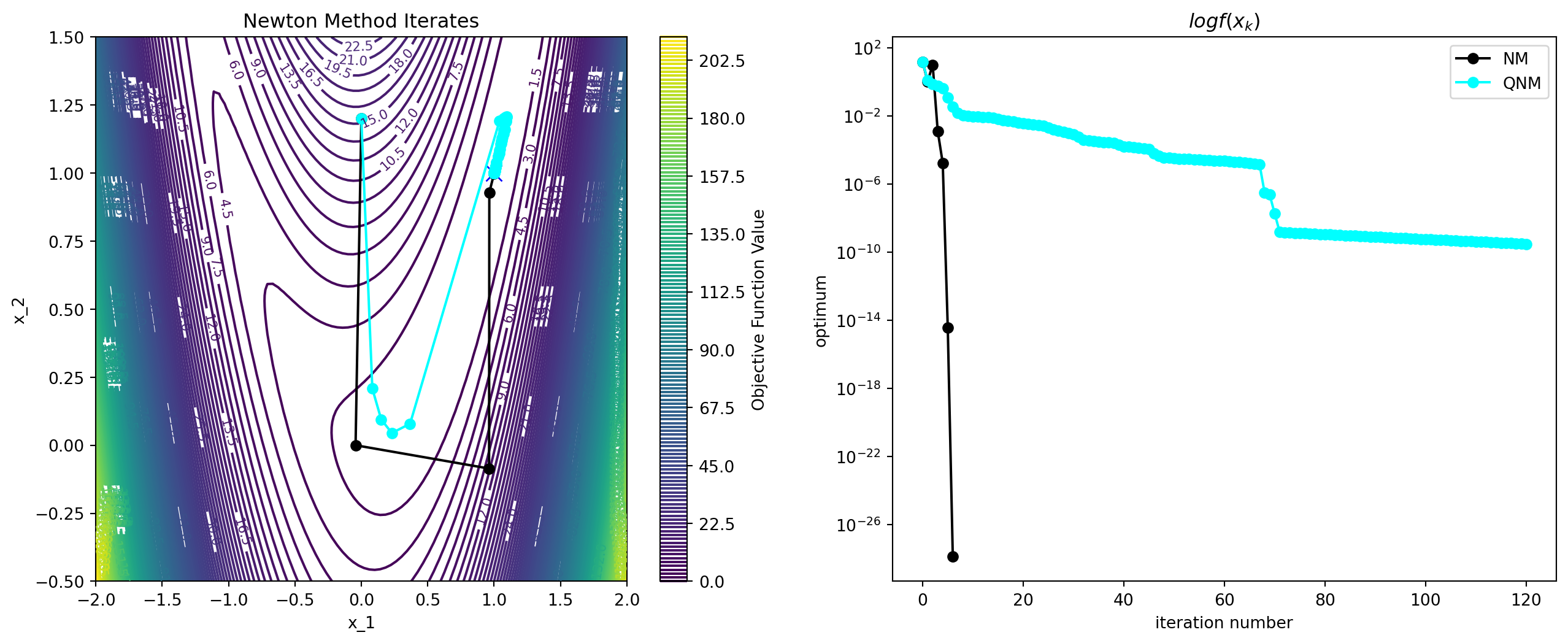
Summary
Summary
You can now minimize (when unconstrained) iteratively. Find LM by
- Choosing direction
- Steepest descent with constant step size is easy and reliable but slow
- Newton method is fast but expensive and unreliable
- needs modifications for reliable convergence
- Quasi-newton methods are a balance, but tricky
- Choosing step size
- Back-tracking for SD and modified NM improves performance
- Strong Wolfe conditions for Quasi-newton methods
- Not tackled: constraints, expensive /, discrete , non-smooth
Systems Optimization I • ME 647 Home